Data security is a critical priority for systems administrators and tech professionals managing complex infrastructure. Hardware redundancies fail, sophisticated ransomware bypasses endpoint protection, and natural disasters compromise primary data centers. Implementing a robust, fault-tolerant disaster recovery architecture is essential to ensure operational continuity. The 3-2-1 backup rule remains the gold standard for comprehensive data resilience, providing a systematic framework to protect vital assets against catastrophic loss.
While the fundamental concept is decades old, modern enterprise environments require an advanced execution of this protocol. Integrating cutting-edge storage technologies, cryptographic protocols, and automated failover systems transforms the 3-2-1 backup rule methodology from a basic safeguard into a highly sophisticated defense mechanism.
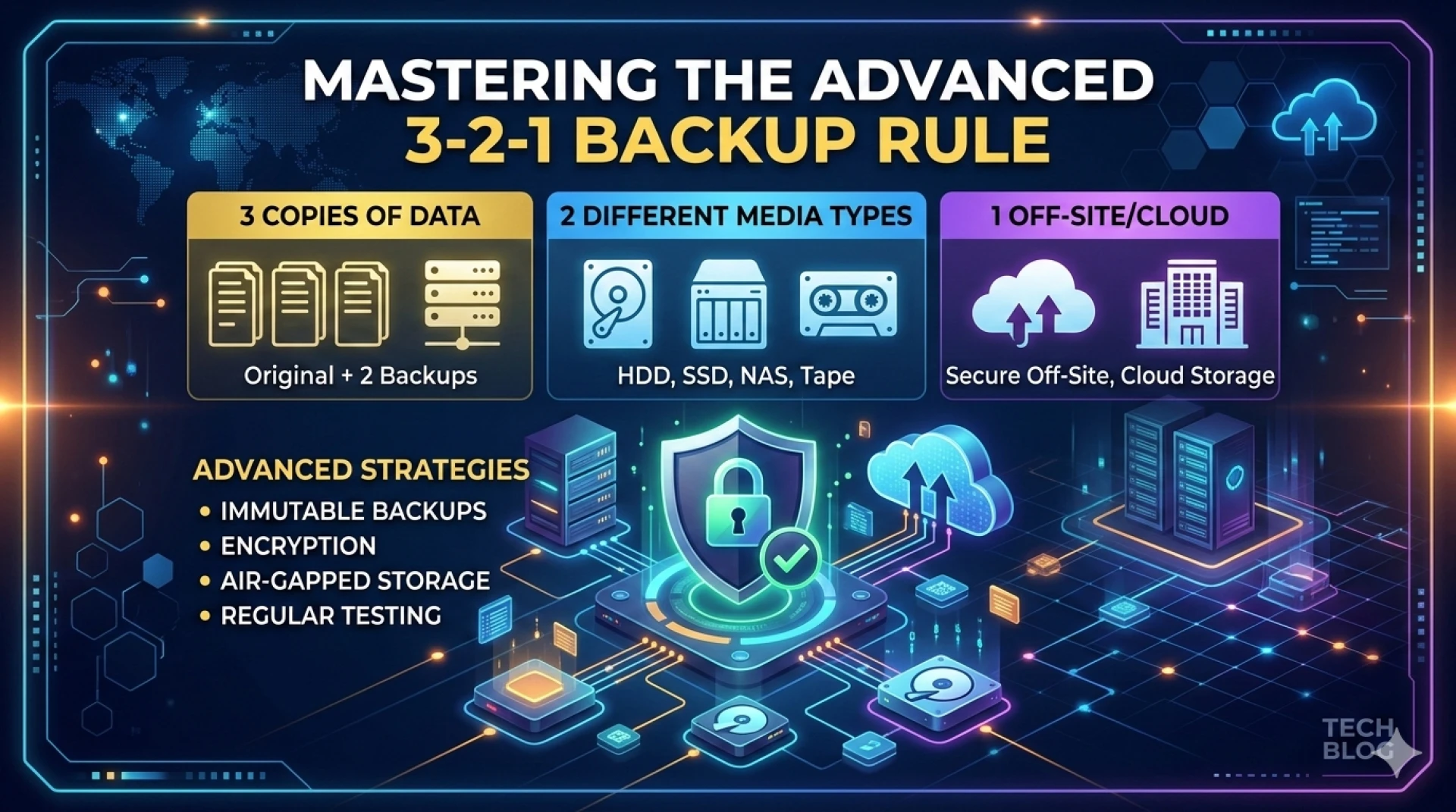
The Architecture of the 3-2-1 Backup Rule
The 3-2-1 backup rule dictates a specific topology for data redundancy. To achieve true resilience, systems must adhere to three core pillars of distribution.
Three Total Copies of Data
Relying on a single backup creates a single point of failure. The rule mandates maintaining the primary production data alongside two distinct backup copies. In high-availability environments, this often translates to active production storage, a local high-speed recovery target, and an archival repository. This triplication ensures that if the production environment and the primary backup are simultaneously compromised—such as during a targeted ransomware attack—a third, isolated copy remains intact.
Two Different Storage Media Types
Storing all backup iterations on identical media exposes the architecture to vendor-specific vulnerabilities or universal hardware degradation. Advanced implementations require diversifying the underlying technology. You might combine a local Network Attached Storage (NAS) utilizing NVMe solid-state drives for rapid localized recovery with high-capacity LTO-9 magnetic tape or a distinct Storage Area Network (SAN) architecture. This hardware heterogeneity mitigates the risk of simultaneous firmware failures or localized physical damage.
One Offsite Location
Physical separation is the final requirement. At least one backup copy must reside in a geographically distinct location to protect against site-wide disasters. For modern tech enthusiasts and enterprise IT, this usually means utilizing enterprise-grade cloud storage solutions. Solutions like AWS S3 Glacier or Azure Blob Storage provide scalable, highly durable offsite repositories.
Executing a Comprehensive Backup Strategy
Deploying this architecture requires meticulous planning and the integration of physical hardware with cloud infrastructure. Start by establishing a local backup target designed for high throughput. A local NAS configured in RAID 6 or ZFS (Zettabyte File System) provides fault tolerance and enables rapid restoration for minor localized incidents.
Next, implement an automated synchronization protocol to push encrypted data to an offsite cloud repository. Utilize an immutable object storage configuration—often referred to as Write Once, Read Many (WORM)—to ensure that once data is written to the cloud, it cannot be altered or deleted by malicious actors or compromised administrator credentials. Enable continuous data protection (CDP) or high-frequency snapshotting to minimize the Recovery Point Objective (RPO).
Common Implementation Mistakes to Avoid
Even seasoned tech professionals can make architectural errors when configuring disaster recovery systems. Avoid these frequent pitfalls to maintain data integrity:
- Failing to air-gap backups: If your local backups remain continuously accessible from the primary network, lateral ransomware movement can encrypt both the production data and the backup repository. Implement strict network segmentation or physical air-gapping.
- Neglecting restoration testing: A backup is fundamentally useless if the restoration process fails. Regularly conduct automated disaster recovery drills to verify data integrity and measure your Recovery Time Objective (RTO).
- Insufficient cryptographic controls: Data must be encrypted both at rest and in transit. Utilize AES-256 encryption managed by a secure, centralized key management server to prevent unauthorized data exfiltration.
Securing Your Digital Infrastructure
Achieving ultimate data resilience requires constant vigilance and a commitment to systematic disaster recovery protocols. The 3-2-1 backup rule provides the essential blueprint for an advanced, fault-tolerant data security strategy. By leveraging diverse hardware, leveraging immutable cloud storage, and strictly avoiding common architectural flaws, you ensure complete peace of mind.
Take the time to audit your current storage topology. Evaluate your backup appliance media, test your restoration latency, and verify that your offsite repositories are truly isolated from your primary domain.


