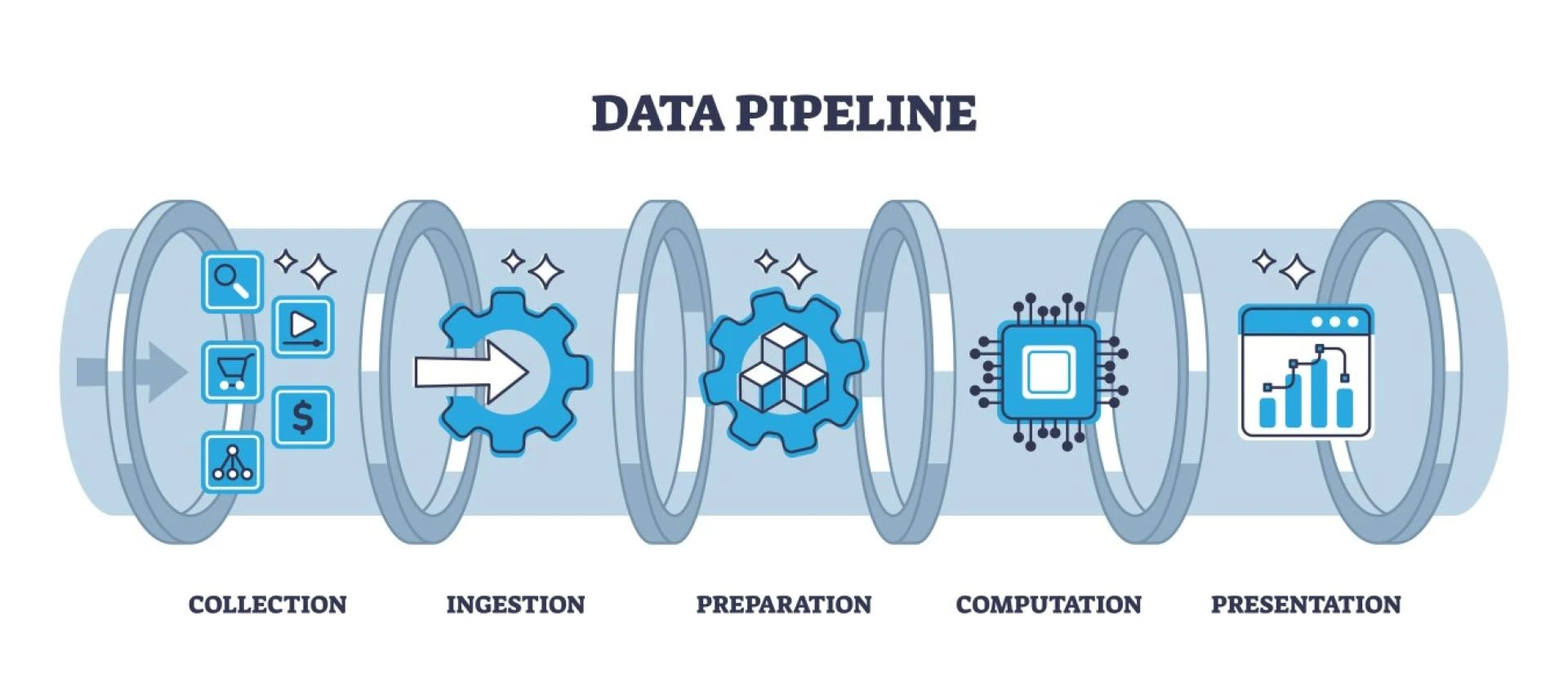
Data plays a central role in every modern organization. From customer behavior patterns to operational intelligence, businesses depend heavily on real time and batch information flows to make decisions. However, simply collecting data is not enough. What truly enables insights is a structured process that moves information from diverse sources to destinations where it becomes usable. This structured process is often discussed through resources such as end-to-end data pipeline development, which outline how organizations can design scalable systems that manage the full data lifecycle.
Today’s data-driven world demands systems that are automated, reliable, secure, and capable of handling both rapid ingestion and complex transformation. Whether a company operates in ecommerce, finance, healthcare, education, or logistics, it must depend on a well-designed pipeline framework to maintain performance and accuracy.
This article provides a comprehensive, expert-level explanation of how modern pipelines work, what components they include, the architectural patterns used in enterprises, pricing expectations, tool selections, implementation best practices, and answers to common questions. Everything you need to understand the pipeline landscape is explained in a clear, practical, and professional manner.
What Modern Pipelines Aim to Solve
The primary goal of a modern data workflow is to enable the smooth transition of information from raw sources to meaningful output. Companies encounter a wide variety of challenges that make this process difficult without proper pipelines in place.
Data from multiple systems
Businesses pull information from CRM tools, ERP databases, marketing platforms, IoT sensors, websites, mobile apps, payment systems, and more. Each of these systems produces data in different formats, frequencies, and quality levels.
Rising data volume
Organizations experience a rapid increase in volume due to more online activity, automated processes, and user-generated content. Scalable pipelines ensure that datasets remain manageable no matter how fast they grow.
Demand for faster insights
Executives and product teams want real time dashboards, predictive analytics, and machine learning outcomes without delays. Manual processes cannot support these expectations.
Governance and accuracy
Regulatory standards, internal audit requirements, and cross-department reporting all require data to be accurate, validated, and consistent.
A modern pipeline addresses all these concerns while enabling teams to work efficiently and confidently.
Core Components of a Complete Pipeline Framework
To understand how data flows from start to end, examining each component individually helps build a clearer picture.
1. Data Ingestion
This step captures information from multiple sources. Ingestion may occur in two ways:
- Batch ingestion for scheduled or periodic loading
- Streaming ingestion for constant, real time information flow
Tools commonly used include Kafka, AWS Kinesis, Google Pub/Sub, Apache NiFi, and Flink Connectors.
2. Storage Layer
Once data enters the system, it needs a secure, scalable place to reside. Organizations rely on:
- Cloud object storage
- Data lakes
- Data warehouses
- Distributed file systems
Systems like S3, Azure Blob, GCS, Snowflake, BigQuery, and Delta Lake are often used.
3. Transformation and Processing
Transformation ensures that raw input is cleaned, enriched, and aligned with business requirements. This step may include:
- Data cleansing
- Normalization
- Schema standardization
- Feature engineering
- Aggregations
- Deduplication
Apache Spark, dbt, Beam, Glue, Databricks, and Flink are common tools.
4. Workflow Orchestration
Orchestration coordinates the entire pipeline, ensuring each stage runs in the right order and handles failures gracefully. Popular orchestration platforms include Airflow, Prefect, Dagster, and Managed Workflows on AWS.
5. Quality and Governance
Pipelines must validate correctness by checking:
- Null patterns
- Schema mismatches
- Duplicates
- Range violations
- Unexpected spikes or drops
Tools like Great Expectations and Soda Core support quality automation.
6. Delivery and Consumption
The final step pushes cleaned data to:
- BI tools
- Machine learning models
- Operational systems
- Reporting dashboards
- APIs
This ensures different teams can use the processed information without friction.
Popular Architectural Patterns
Different organizations choose different designs depending on scale, complexity, and performance needs.
Layered Architecture
This is a multi-stage approach where data passes through raw, cleansed, and curated layers. It provides strong governance, easy debugging, and structured lineage.
Lakehouse Architecture
A lakehouse combines the openness of a data lake with the structure of a warehouse. It allows advanced analytics, ML workflows, and real time processing with strong governance.
Event Driven Architecture
Event driven pipelines work well for real time applications such as fraud detection, logistics tracking, live dashboards, and IoT operations.
Microservices Based Data Flow
Microservices divide pipeline functions into independent units. Each service performs a specific task and communicates using lightweight APIs or messaging systems.
ELT Focused Cloud Architecture
With powerful cloud warehouses, companies often skip heavy transformations before loading. Data is loaded in its raw state and transformed inside the warehouse, enabling faster scaling.
Benefits of a Well Designed Pipeline
A complete pipeline system provides wide-ranging benefits for both operational teams and strategic decision makers.
Better data consistency
Automated rules maintain uniform definitions across departments, ensuring that reports match and decisions remain aligned.
Faster analytics
Teams access reliable insights with minimal delay, enabling faster experimentation, improved forecasting, and quicker strategic decisions.
Reduced operational overhead
Automation minimizes manual data handling while reducing errors and maintenance efforts.
Support for AI and machine learning
Cleaned and structured datasets accelerate model development, feature engineering, and monitoring.
Cost optimization
Companies avoid running oversized systems and unnecessary manual processes while improving resource utilization.
Resilience and fault tolerance
Good pipelines expect failures and recover automatically, eliminating downtime risks.
Common Tools Used in Industry
Organizations typically assemble pipelines using tools from the following categories:
- Orchestration Airflow, Prefect, Dagster
- Processing Spark, Flink, Beam, Snowpark
- Ingestion Kafka, NiFi, Kinesis, Pub/Sub
- Storage S3, BigQuery, Snowflake, Delta Lake
- Quality Great Expectations, Soda
- Visualization Power BI, Tableau, Looker
Choosing the right combination depends on cost, data volume, team expertise, and performance needs.
Pricing Trends for Pipeline Implementations
Pipeline pricing varies depending on infrastructure choices, cloud usage, team size, and processing frequency. Below are common cost factors:
Cloud storage
Pay as you go models mean cost rises with volume. Data lakes are usually cheaper than warehouses for raw storage.
Compute
Processing engines such as Spark, Flink, or warehouse compute consume the largest share of cost, especially during transformations and ML workloads.
Orchestration
Self hosted orchestration is cheaper but requires maintenance. Managed workflow services cost more but reduce operational burden.
Monitoring and quality checks
Quality tools may follow a subscription model.
Engineering workforce
Experienced data engineers, architects, and analysts add labor cost, especially for complex or large scale designs.
Overall, organizations often invest more initially but observe long term savings because efficient pipelines reduce inefficiency, duplication, and manual debugging.
Practical Tips for Building a Pipeline from Scratch
Organizations building their first full pipeline system should follow expert recommended strategies.
Start small and scale gradually
Instead of building everything at once, begin with a minimal workflow and expand as datasets grow.
Choose cloud native tools
Cloud platforms provide scalability, reliability, and easier management.
Implement strong data contracts
Clear rules ensure upstream systems never break downstream consumers.
Automate testing
Test transformations, schemas, and quality rules before deployment.
Maintain version control
Track datasets, transformation scripts, and configurations for auditability.
Document everything
Documentation helps future engineers understand decisions, logic, and flow designs.
Use monitoring and alerting
Real time alerts prevent data inconsistencies from spreading into reports or machine learning models.
Common Mistakes to Avoid
Many companies face challenges because of avoidable mistakes.
- Relying on manual processes
- Ignoring schema evolution
- Lacking clear governance policies
- Overusing custom scripts instead of proven frameworks
- Neglecting testing
- Building overly rigid pipelines
- Ignoring security best practices
Avoiding these mistakes improves reliability, resilience, and scalability.
Short FAQ
What is the main purpose of a data pipeline
Its purpose is to reliably move, process, and deliver information so businesses can use it for reporting, analytics, and AI.
How long does it take to build a complete pipeline
Small workflows may take a few days while complex enterprise designs can take weeks or months depending on requirements.
Which cloud platform is best for pipeline workloads
AWS, Google Cloud, and Azure all support strong pipeline ecosystems. The ideal choice depends on your existing environment and budget.
Do pipelines support both real time and batch data
Yes. Modern systems support both modes depending on business needs.
What makes a pipeline reliable
Automation, monitoring, testing, and quality checks ensure that the pipeline produces accurate and consistent results.