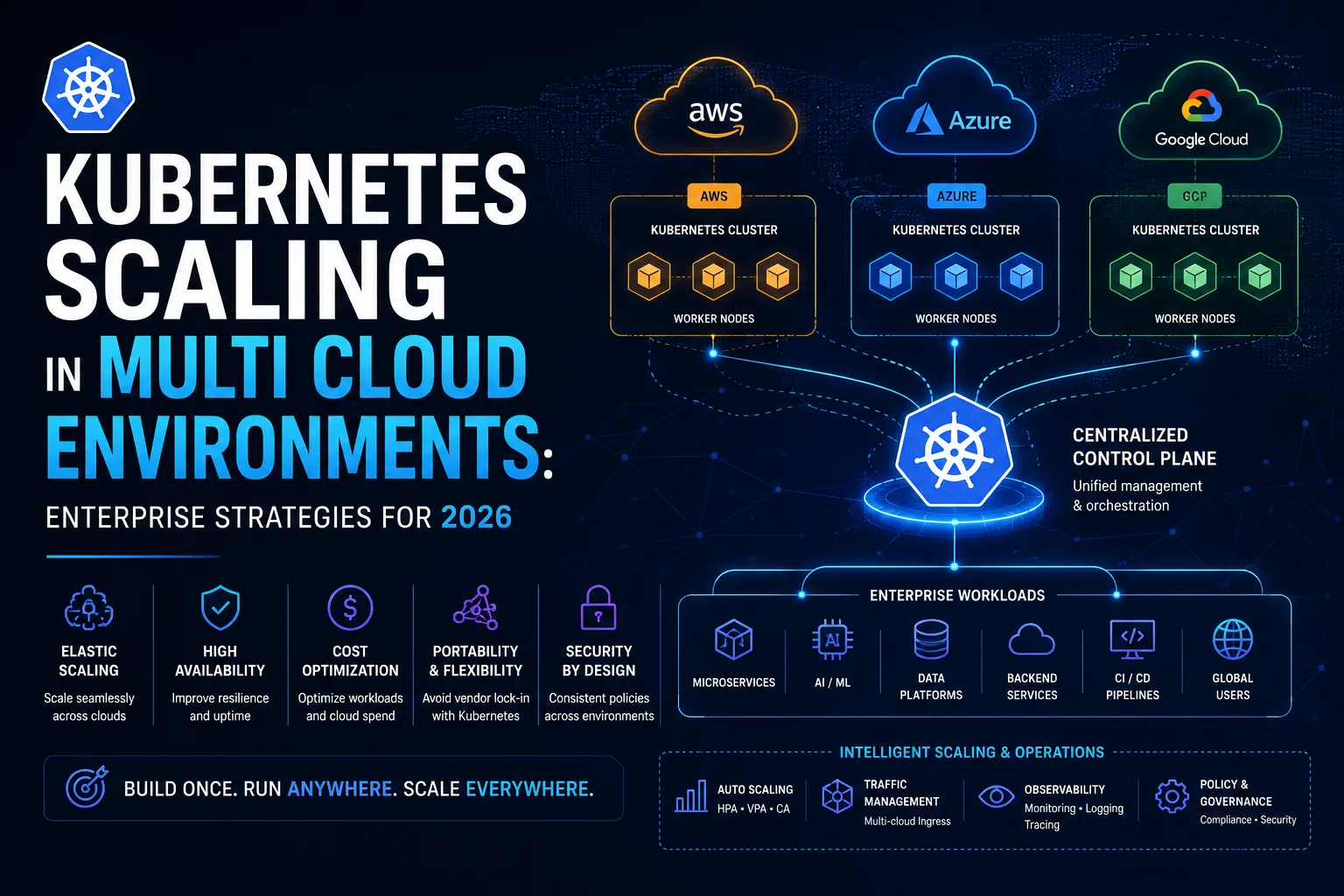
Modern enterprises are no longer scaling applications within a single cloud environment. Organizations today operate across AWS, Azure, Google Cloud, private infrastructure, edge environments, and regional cloud providers simultaneously. As cloud-native systems become more distributed, Kubernetes scaling multi cloud environments has become one of the most important operational challenges for enterprises building resilient and globally distributed digital platforms in 2026.
This shift is being driven by several major trends. AI-native applications now require distributed GPU infrastructure across multiple providers. Global SaaS platforms need low-latency deployment strategies spanning different regions and cloud ecosystems. Enterprises increasingly prioritize workload portability to avoid vendor lock-in while maintaining high availability and operational resilience. At the same time, rising infrastructure costs and evolving compliance requirements are pushing organizations toward more flexible multi cloud deployment strategies.
Kubernetes has emerged as the operational foundation enabling this transition because it provides a standardized orchestration layer capable of managing workloads consistently across heterogeneous environments. However, scaling Kubernetes in multi cloud environments is significantly more complex than scaling a single-cluster deployment. Organizations must now manage distributed networking, cluster orchestration, workload scheduling, autoscaling policies, observability, security governance, infrastructure automation, and cross-cloud workload optimization simultaneously.
This complexity increases even further for enterprises supporting:
- Real-time analytics systems
- AI inference workloads
- Distributed microservices
- Event-driven applications
- Multi-region SaaS platforms
- Global APIs
- Edge-native systems
- High-throughput transactional infrastructure
Recent enterprise infrastructure research shows that Kubernetes is increasingly becoming the default operational platform for distributed infrastructure because organizations require scalable orchestration capable of supporting AI pipelines, stateful workloads, and globally distributed applications across multiple environments.
At the same time, businesses are discovering that scaling Kubernetes across multiple clouds requires much more than provisioning additional clusters. Modern multi cloud Kubernetes scaling involves infrastructure standardization, intelligent workload placement, policy-driven automation, GitOps workflows, service mesh networking, FinOps optimization, and AI-driven autoscaling systems capable of balancing performance, cost, and operational reliability dynamically.
This guide explains how Kubernetes scaling works in multi cloud environments, the operational challenges enterprises face, the architectural strategies organizations use today, and the best practices required to scale distributed Kubernetes infrastructure successfully in 2026.
Why Kubernetes Scaling in Multi Cloud Environments Has Become Critical
The rapid growth of distributed cloud-native infrastructure has fundamentally changed how organizations think about scalability.
In traditional cloud environments, scaling generally involved increasing resources within a single provider region or availability zone. Modern enterprises, however, increasingly operate across multiple cloud ecosystems simultaneously. This shift is driven by the need for:
- Global application performance
- Workload resilience
- Infrastructure portability
- Regulatory compliance
- AI infrastructure flexibility
- Regional redundancy
- Cost optimization
Kubernetes enables organizations to standardize orchestration across environments while maintaining operational consistency. However, scaling distributed Kubernetes infrastructure introduces operational challenges that do not exist in single-cloud environments.
For example, an ecommerce platform may run customer-facing APIs across AWS and Google Cloud simultaneously to optimize regional performance. A fintech organization may deploy regulated workloads inside private cloud infrastructure while using Azure for enterprise integrations and Google Cloud for AI analytics. AI-native SaaS platforms may dynamically schedule GPU-intensive workloads across multiple providers based on GPU availability and pricing conditions.
In these scenarios, scaling decisions must account for:
- Cross-cloud latency
- Workload affinity
- Data locality
- GPU allocation
- Network egress costs
- Compliance restrictions
- Regional failover requirements
This is why Kubernetes scaling multi cloud infrastructure has become a platform engineering and operational architecture problem rather than simply an autoscaling configuration issue.
The rise of AI infrastructure is accelerating this complexity further. AI inference systems often require dynamic scaling across distributed GPU clusters operating in multiple cloud providers simultaneously. Kubernetes increasingly functions as the orchestration layer coordinating these environments while supporting workload portability and operational resilience. Enterprise Kubernetes adoption research continues highlighting AI infrastructure scaling as one of the biggest drivers behind multi-cluster Kubernetes growth globally.
How Kubernetes Scaling Works Across Multi Cloud Infrastructure
Scaling Kubernetes in multi cloud environments involves several interconnected operational layers working together simultaneously.
At the infrastructure level, enterprises generally operate multiple Kubernetes clusters distributed across:
- Cloud providers
- Geographic regions
- Edge systems
- Private data centers
- GPU environments
- Development and production platforms
Each cluster typically scales independently while remaining connected through centralized governance and orchestration systems.
Kubernetes scaling itself occurs at several levels simultaneously. Pod autoscaling adjusts application replicas dynamically based on metrics such as CPU utilization, memory consumption, request throughput, queue depth, or custom business signals. Node autoscaling provisions additional compute infrastructure when cluster resource capacity becomes constrained. Cluster-level orchestration coordinates workload placement across distributed environments.
In multi cloud environments, scaling decisions become significantly more sophisticated because workloads may need to move dynamically across cloud providers depending on:
- Resource availability
- Infrastructure pricing
- GPU capacity
- Regional traffic patterns
- Operational health
- Compliance constraints
Modern enterprises increasingly use GitOps workflows and infrastructure-as-code systems to standardize scaling operations across distributed environments. GitOps has become foundational for Kubernetes scaling because it improves deployment consistency, rollback reliability, auditability, and operational governance. Organizations increasingly use platforms such as ArgoCD, FluxCD, Cluster API, and Rancher to coordinate scaling and lifecycle management across multi-cluster infrastructure.
Service mesh architecture also plays an increasingly important role in multi cloud scaling. Distributed Kubernetes environments require secure and efficient communication between workloads operating across different clusters and cloud providers. Service meshes such as Istio and Linkerd help organizations standardize:
- Traffic routing
- Service discovery
- Encryption
- Cross-cluster communication
- Observability
- Failure handling
Without centralized traffic management, scaling distributed workloads becomes operationally unstable.
Modern Kubernetes scaling also increasingly depends on observability systems capable of providing real-time visibility into:
- Cluster health
- Resource utilization
- GPU allocation
- Network latency
- Infrastructure costs
- Application performance
- Security events
Distributed observability is becoming essential because engineering teams cannot optimize scaling decisions effectively without centralized operational visibility.
The Biggest Challenges in Kubernetes Multi Cloud Scaling
Although Kubernetes provides enormous flexibility for distributed infrastructure, scaling multi cloud environments introduces substantial operational complexity.
One of the biggest challenges is operational fragmentation. Every cloud provider introduces different APIs, networking models, IAM systems, storage abstractions, and managed services. Without standardization, engineering workflows quickly become inconsistent across environments.
Networking complexity is another major issue. Cross-cloud communication introduces latency variability, traffic routing challenges, DNS management complexity, and high egress costs. Organizations must carefully optimize workload placement to minimize unnecessary cross-region traffic while maintaining application responsiveness.
Cost optimization also becomes significantly more difficult in distributed Kubernetes infrastructure. Multi cloud environments often suffer from:
- Idle clusters
- Unoptimized autoscaling
- Resource fragmentation
- Overprovisioned GPU infrastructure
- Unnecessary inter-region traffic
This is why Kubernetes FinOps has become increasingly important for enterprises operating large-scale distributed environments.
Security fragmentation represents another major operational challenge. Different cloud providers implement identity management and security controls differently. Organizations must standardize:
- Access management
- Runtime security
- Network policies
- Secrets management
- Supply chain security
- Compliance enforcement
across all environments simultaneously.
Observability also becomes increasingly difficult as cluster counts grow. Large enterprises often operate dozens or even hundreds of Kubernetes clusters spanning multiple regions and providers. Without centralized observability systems, diagnosing failures and optimizing scaling decisions becomes extremely difficult.
Skill gaps remain another significant barrier. Scaling Kubernetes across multiple clouds requires expertise spanning:
- Kubernetes operations
- Platform engineering
- Cloud-native networking
- Infrastructure automation
- Security engineering
- AI infrastructure orchestration
- Observability systems
Many enterprises struggle to build internal teams capable of managing this complexity effectively.
Enterprise Strategies for Scaling Kubernetes Across Multi Cloud Environments
Enterprises successfully scaling Kubernetes across multi cloud infrastructure generally follow several consistent operational strategies.
One of the most important strategies is infrastructure standardization. Organizations increasingly minimize provider-specific customization and use Kubernetes-native abstractions wherever possible. This improves workload portability while reducing operational inconsistency across environments.
Platform engineering has also become central to Kubernetes scaling strategy. Enterprises increasingly build internal developer platforms designed to abstract Kubernetes complexity away from application teams while maintaining operational consistency globally. These platforms standardize:
- Deployment workflows
- Security policies
- Observability
- Infrastructure automation
- Scaling operations
GitOps has become another foundational operational strategy. Declarative infrastructure management significantly reduces operational drift and improves deployment reliability across distributed environments.
Organizations are also increasingly adopting centralized policy-as-code governance systems to standardize:
- Security enforcement
- Compliance controls
- Resource allocation
- Deployment validation
- Runtime policies
across all clusters automatically.
Another major strategy involves workload segmentation. Not every workload needs to run across every cloud provider. Enterprises increasingly place workloads strategically based on:
- Latency requirements
- GPU availability
- Compliance obligations
- Data residency
- Infrastructure pricing
- Regional traffic patterns
AI-driven autoscaling is also becoming more important in large-scale Kubernetes environments. Traditional Kubernetes autoscaling systems are often reactive and metric-driven, which can create inefficiencies under dynamic workloads. Emerging AIOps-driven scaling systems increasingly combine forecasting, workload prediction, and business-level policies to optimize scaling decisions proactively. Recent Kubernetes autoscaling research demonstrates that AI-driven scaling systems can significantly improve infrastructure efficiency and reduce operational stress in dynamic workloads.
The Future of Kubernetes Multi Cloud Scaling
The future of Kubernetes scaling will increasingly revolve around automation, AI-native infrastructure, and autonomous operations.
Several major trends are already shaping the next generation of Kubernetes scaling strategies:
- AI-powered autoscaling
- Intent-driven infrastructure management
- Self-healing clusters
- Autonomous workload orchestration
- Distributed AI inference scheduling
- Edge-native Kubernetes operations
- Predictive infrastructure optimization
AI infrastructure is becoming one of the biggest drivers of Kubernetes evolution because distributed AI workloads require orchestration across GPUs, edge systems, and cloud providers simultaneously. Kubernetes increasingly functions as the operational coordination layer for these environments.
Organizations are also moving toward intent-based infrastructure management where engineering teams define performance and operational objectives while automation systems dynamically handle:
- Workload placement
- Infrastructure scaling
- Resource optimization
- Policy enforcement
- Failure recovery
This shift will likely transform Kubernetes operations significantly over the next several years.
Final Thoughts
Kubernetes scaling multi-cloud infrastructure has become one of the most important operational challenges facing modern enterprises in 2026. Organizations increasingly operate distributed applications across multiple cloud providers, private infrastructure, AI environments, and edge systems simultaneously, making scalable Kubernetes orchestration critical for modern digital operations.
However, successful multi cloud Kubernetes scaling requires far more than provisioning additional clusters or enabling autoscaling policies. Modern enterprise environments now depend on GitOps automation, platform engineering, service mesh networking, centralized observability, runtime security enforcement, infrastructure standardization, and intelligent workload orchestration across distributed systems.
Businesses investing in Kubernetes multi cloud scaling gain significant operational advantages involving resilience, workload portability, AI infrastructure flexibility, regulatory adaptability, and global deployment agility. At the same time, organizations must manage the complexity that distributed infrastructure introduces.
The enterprises that succeed will be the ones that treat Kubernetes scaling as a long-term platform engineering and operational architecture discipline rather than simply a container orchestration problem.


