Enterprise data architecture demands rigorous continuity protocols. System administrators and infrastructure architects constantly navigate the persistent threats of hardware degradation, site-wide disasters, and cryptographic cyber attacks.
The 3-2-1 backup rule provides a foundational, systematic framework for mitigating these catastrophic data loss vectors.
By distributing data across multiple failure domains, organizations establish a robust defense mechanism. This methodology is heavily relied upon to maintain operational continuity and ensure that critical datasets survive localized anomalies. Implementing this protocol requires precise execution and a comprehensive understanding of underlying storage topologies.
Understanding the mechanics behind this strategy allows IT teams to engineer highly resilient environments. The core principles dictate specific hardware and geographical requirements that directly counteract standard vulnerabilities found in flat storage networks.
Eliminating Single Points of Failure
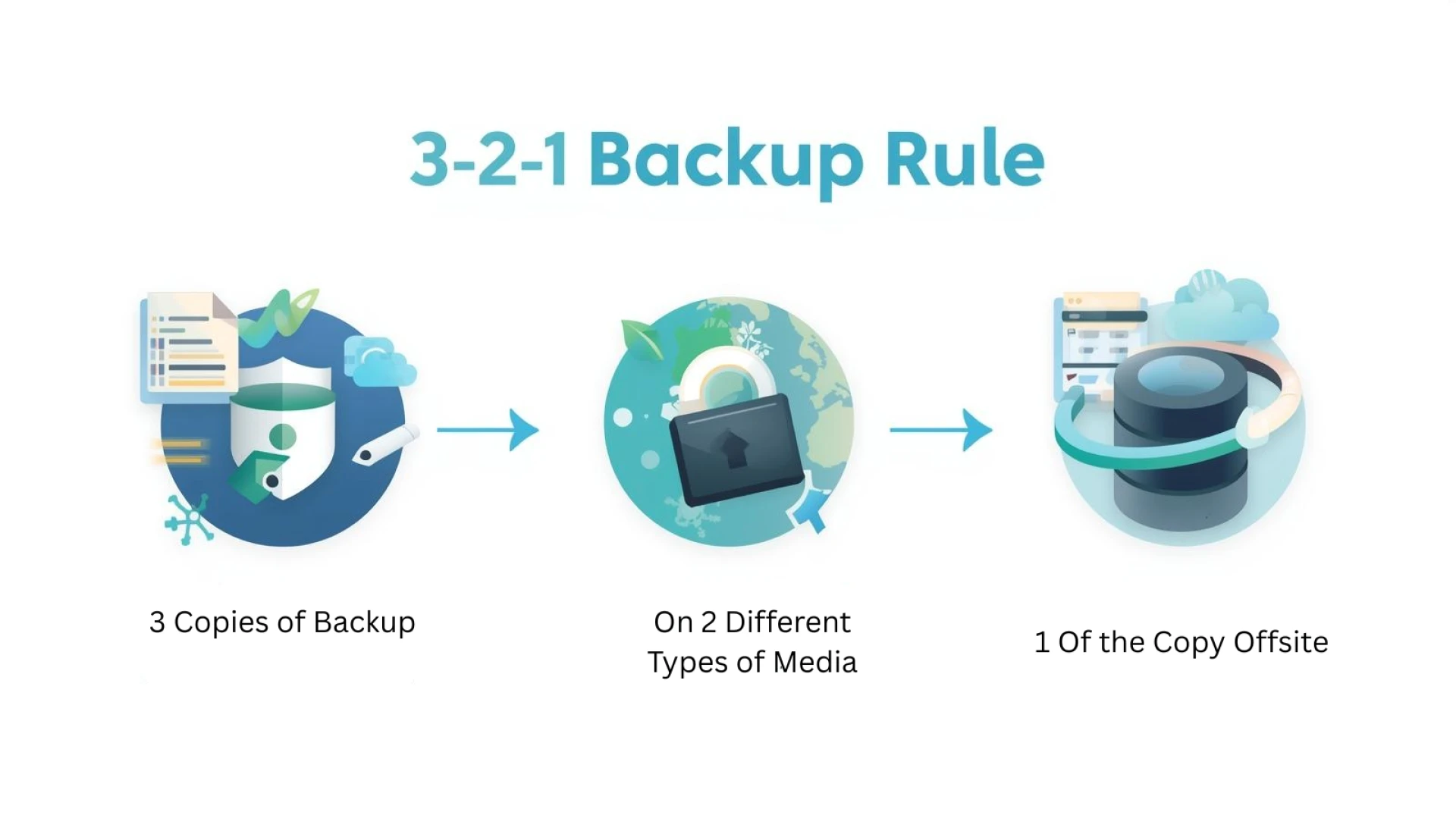
The primary directive of this architecture mandates maintaining three distinct copies of critical data. This operational standard includes the primary production dataset alongside two independent backup iterations. Relying on a single backup target creates an unacceptable single point of failure within the storage infrastructure.
Maintaining three copies mathematically reduces the probability of concurrent data corruption. If the primary storage array experiences a catastrophic drive failure, and the first backup target suffers from simultaneous logical corruption, the tertiary copy guarantees data survival.
Mitigating Correlated Hardware Risks
Storing data copies on two different storage media types systematically addresses hardware-level vulnerabilities. Correlated risks occur when uniform storage arrays share identical firmware distributions or hardware controllers. A specific software bug or controller failure could compromise identical systems simultaneously.
Deploying a heterogeneous storage environment prevents these synchronized failures. An organization might pair a primary solid-state drive (SSD) SAN with a secondary network-attached storage (NAS) utilizing rotational disks, or rely on linear tape-open (LTO) physical media. This physical and mechanical diversity ensures that a defect affecting one storage tier cannot automatically propagate to the redundancy tier.
Securing Data with Offsite Exigency
The offsite requirement dictates that at least one backup replica must reside in a geographically distinct location. Physical separation is critical for comprehensive disaster recovery following power grid failures, natural disasters, or total facility compromises. A localized incident that destroys the primary data center will also destroy any localized backups.
Modern implementations heavily utilize immutable cloud repositories or air-gapped physical locations to fulfill this requirement. Cloud object storage configured with Object Lock (WORM capabilities) ensures that offsite data cannot be modified or deleted by unauthorized internal or external actors. This geographical isolation physically insulates the backup copy from network-traversing threats.
Integrating the 3-2-1-1-0 Protocol
As threat vectors evolve, enterprise environments must adapt to sophisticated ransomware attacks by adopting the extended 3-2-1-1-0 methodology. This advanced framework introduces critical safeguards specifically designed for modern cyber threats.
The additional "1" requires keeping at least one backup copy completely offline, air-gapped, or entirely immutable. This prevents automated ransomware scripts from encrypting the backup repository. The "0" mandates automated verification protocols, utilizing cyclic redundancy checks (CRC) and synthetic full backups to ensure zero errors exist within the repository. Automated validation guarantees that recovery data is fully uncorrupted and immediately restorable during critical incidents.
Balancing RTO and Cost-Efficient Redundancy
Optimizing your backup appliance infrastructure requires aligning these redundancy protocols with your organization's specific Recovery Time Objectives (RTO). High-performance, highly available storage tiers significantly reduce recovery times but drastically increase capital and operational expenditures.
Organizations must conduct a thorough business impact analysis to tier data appropriately. Mission-critical databases might require immediate replication to a secondary hot site, while archival data can reside safely on cost-efficient, deep-glacier cloud storage. Audit your existing architecture immediately to identify single points of failure, calculate your storage medium diversity, and integrate immutable offsite solutions into your disaster recovery roadmap.


