What Is The Ultimate Guide To Scrape Reviews Online?
As we know data is the most necessary component for web scraping review data. A review management platform is powered by online reviews, such as a car is powered by energy or gas. While there are various sources of user reviews such as ReviewGator’s Review Scraper API.

As a result, we set out to address our own challenges, and we’ve learned a lot in the process. We began by using these product reviews in our own tool but quickly discovered that we could market this technology so that others could advantage from such an easy API rather than scraping reviews manually.
This was a turning point in our capacity to invest more heavily in this product, not only for ourselves but also for paying users. Following are some of the lessons we learned along the journey.
API vs Scraping

In an ideal society, review data would be accessible using API, however, that’s not the case. We employ APIs whenever possible, however, the majority of the 85+ review sites from which we get information don’t have APIs, so we have to rely on web scraping. We also have connections with particular review websites in some circumstances.
Select Scraping Library

First and foremost, what programming language would you prefer to use? Which scraping library you use will be determined by this. Python offers Scrapy, Ruby has Nokogiri, and there are plenty of additional possibilities.
There are various factors to consider here, for example: How reliable is the library you’ve selected? How easy is it to find talented programmers who have worked with that library before? Is it scalable in any way?
Our system was written in Ruby because it was my strongest language at the time. This influenced a number of decisions, including the use of Sidekiq for background processing and ActiveAdmin for the admin panel, among others.
At ReviewGators, we create scrapers that follow the specific format:
- Determine the number of pages of reviews that can be paginated.
- Determine which markup contains the reviews.
- Iterate through each review and save the information.
In other circumstances, utilizing a network analyzer is beneficial since some websites load their data via APIs, which are easier to use (and maintain) than parsing code. Another consideration is whether the website is loaded asynchronously, in which case you should employ a headless browser rather than a standard HTTP request.
Concurrency

It’s important to think about how you’ll deal with concurrency when you’ve created the scraper, depending on the scale you’ll be scraping reviews on. We chose Sidekiq to process our operations in the background because it allows us to easily manage many queues and scale vertically and horizontally as needed. We also utilize sidekiq-throttled to make sure we’re not overloading the review site and our vendors with queries.
We started encountering database concurrency issues as our business developed, so we made a number of database adjustments to improve our workload.
Blocking Mechanisms

You’ll very certainly run across blocking mechanisms from the review site(s) in question as you start scaling up. This problem can be solved in various ways:
- Scraping services that allow you to access a URL and have them handle the blocking measures on their end.
- Providers of proxy IP addresses for data centers, homes, and mobile phones.
- Captcha-solving services that automate the process at a large scale.
- Headless browser services make it easier to manage headless browsers on a large scale.
- To get around blocking measures on some sites, you’ll need to send requests with specific headers and/or cookies, as well as a variety of additional techniques.
Duplications

You’ll want to optimize your scraping once you’ve started scraping reviews at scale to stop spending compute and other assets. You’ll probably want to keep retrieving the latest reviews as they come in after you’ve fetched all the reviews from a certain review profile.
To accomplish this, you’ll need to create algorithms that identify which reviews are old and which are new. This is far more difficult than it appears at first, as there are several formatting, pagination, ordering, and other issues. If the review profile has 100 pages, your goal is to stop scraping once you’ve collected all of the most recent reviews, so you don’t have to check all of them every time you check for updates.
Several settings are exposed to our users that encapsulate this complexity:
Diff: This argument allows you to specify a previous work ID for your specified profile, ensuring that only the most recent reviews are returned.
From_date: Reviews from a particular date will only be scrapped.
blocks: The number of blocks to return from the results in tens.
Data Cleaning

Data cleaning is an important element of data extraction since you must always guarantee that the information you consume is in a consistent manner. To begin, we recommend encoding your database to utf8mb4-bin, which supports text in a variety of languages, as well as emoji and other text that you will undoubtedly encounter.
Date formatting is extremely difficult, especially when scraping from various sources. This is due to the fact that there is no universal date format; for example, Americans may use yyyy-mm-dd, while other countries use yyyy-dd-mm. To make matters worse, we’ve observed occasions where the same review site employs several formats.
Aside from that, some websites contain reviews with headers, questions, and other metadata that must be handled.
Monitoring

We consider monitoring as a serious matter. In the worst-case situation, we receive emails from a customer informing us of a problem, which is when our monitoring system kicks in.
- Keep track of the progress of every work that comes through our system.
- Wait and process times per job are being tracked, with averages across sites.
- Keeping track of the performance of our numerous service providers.
- Tests of each review site on a regular basis, comparing expected and real-time outcomes.
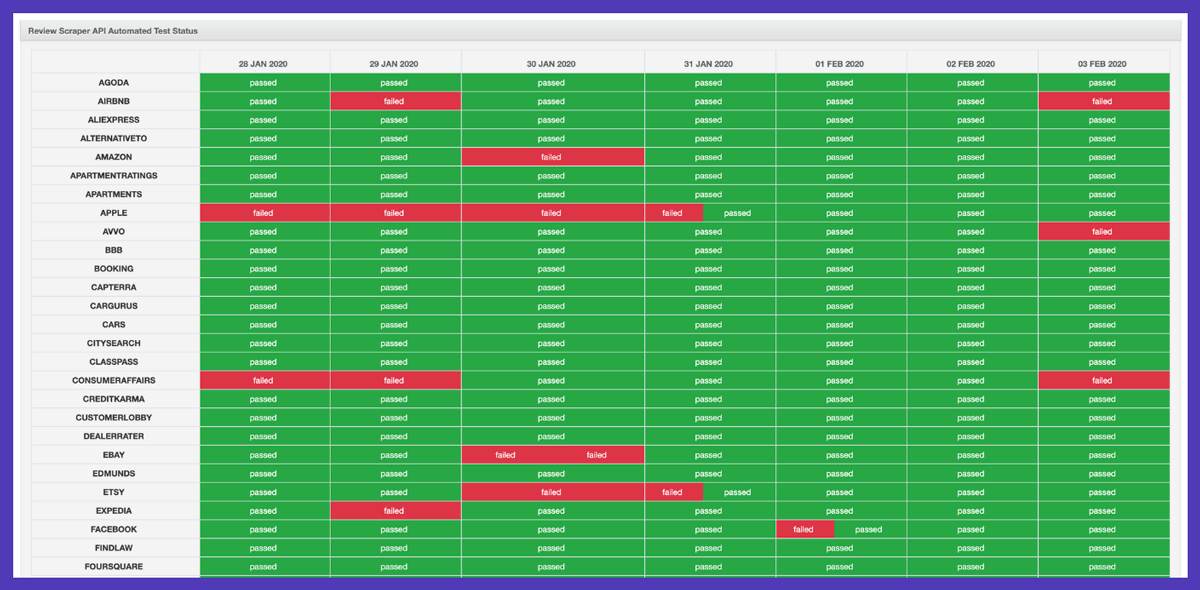
We have a substantially modified ActiveAdmin dashboard that allows us to monitor and intervene as needed. We also utilize Rollbar for real-time analytics and Asana automation to assist with issue management.
Conclusion

Operating a high-quality web scraping business on a large scale is a difficult task. Fortunately, we’ve got our technology available through API, so instead of spending significant technical resources rebuilding the wheel, all you have to do is call two API endpoints.
For more details contact ReviewGators now!!
Request for a quote!!!
0