



In the vast realm of the internet, a remarkable software robot known as a web crawler emerges. With a mission to traverse the digital landscape, it diligently scans, explores, and downloads the wealth of information it encounters. While search engines like Google, Bing, Baidu, and DuckDuckGo often wield these crawlers, their influence extends far beyond. These innovative programs, equipped with their search algorithms, compile an index of collected data. This index empowers search engines to furnish users with relevant links based on their search queries.
Yet, the realm of web crawlers extends further still. Behold The Way Back Machine from the Internet Archive, a distinct breed of crawler driven by a different purpose. It preserves the legacy of websites, capturing snapshots frozen in time, enabling us to journey back and witness the past.
Embark on a voyage of discovery as we unravel the intricate workings of these web crawlers, unlocking their role in automating data exploration and shaping the digital landscape as we know it.
How Does a Web Crawler Work?
Each day, web crawlers, including Google\'s Googlebot, embark on digital expeditions armed with a carefully curated list of websites to explore. This list is called the "crawl budget," representing the resources allocated for indexing web pages. The crawl budget is influenced by two significant factors: popularity and staleness. Highly popular URLs are crawled more frequently to ensure their freshness in the index. Additionally, web crawlers strive to ensure URLs are updated within the index.
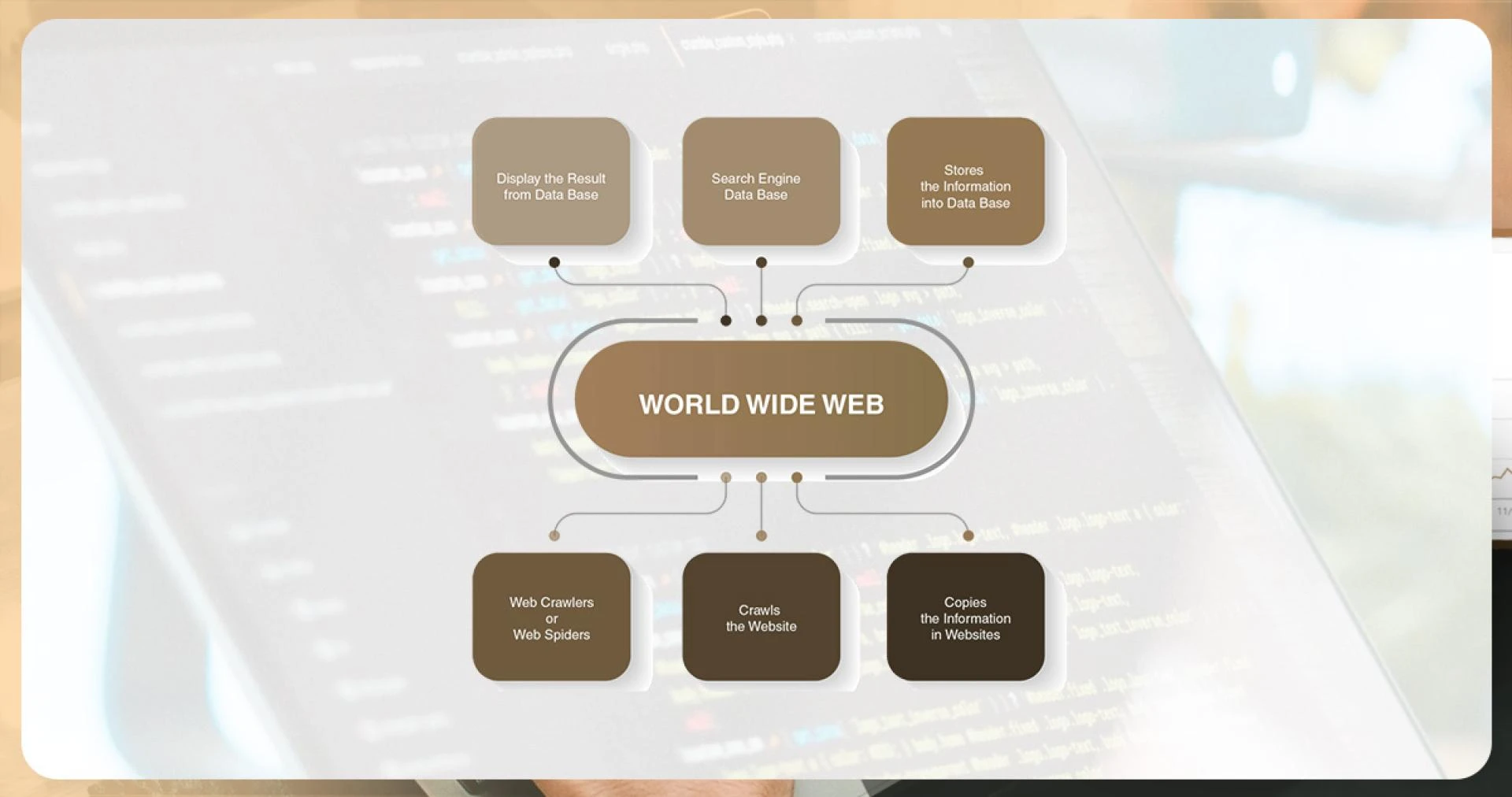
As a web crawler connects to a website, it initiates the process by downloading and parsing the robots.txt file. This file is a part of REP (Robots Exclusion Protocol), a set of standards that govern robots\' behavior during web crawling, content access, indexing, and content delivery to users. Website owners can utilize robots.txt to define which user agents are allowed or disallowed access to specific site areas.
Furthermore, the robots.txt file can include a crawl-delay directive, regulating the pace of requests the crawler makes to the website. It also lists the sitemaps associated with the site, aiding the crawler in discovering and determining the last update of each page. If a page has not undergone any changes since the last visit by the crawler, it will be skipped during the current crawl.
Once a web crawler reaches a page slated for crawling, it renders the page within a browser, fetching the HTML, executing third-party code, processing JavaScript, and styling with CSS. This information is then stored in the search engine\'s database, awaiting the indexing and ranking phase. Simultaneously, the crawler downloads all the links present on the page. Any links not yet indexed by the search engine are added to a list earmarked for future crawling.
Although adherence to the directives outlined in a robots.txt file is voluntary, most major search engines adhere to these guidelines. Surprisingly, even legitimate web crawlers, including the Internet Archive, may overlook these instructions. However, it\'s worth noting that certain bad actors, such as spammers and botnets, disregard robots.txt directives.
Join us as we delve deeper into the intricate journey of web crawlers, unraveling their pivotal role in the efficient data indexing and illuminating the nuances of their interactions within the ever-evolving digital landscape.
What are the Some Examples of Web Crawlers?

Within search engines, many web crawlers tirelessly traverse the vast expanse of the internet. As we zoom in on the search giant Google, we discover a remarkable array of 17 distinct bot personas that fulfill various purposes:
AdSense: This bot focuses on scanning web pages for AdSense advertisements, ensuring their seamless integration.
APIs-Google: Designed to interact with Google APIs, this bot facilitates the smooth functioning of Google\'s various services.
AdsBot Mobile Web: Tasked with mobile web advertising, this crawler optimizes ad placements and performance on mobile devices.
AdsBot Mobile Web Android: Similar to its counterpart above, this crawler specializes in mobile web advertising but specifically targets Android platforms.
Googlebot News: As the name suggests, this bot collects and indexes news content to provide up-to-date information.
Googlebot Image: With a keen eye for visuals, this crawler focuses on exploring and indexing images across the web.
Googlebot Desktop: This versatile bot crawls and indexes web pages for desktop users.
Googlebot Video: Tasked with indexing and cataloging video content, this bot ensures a comprehensive search experience for users seeking video-based results.
Googlebot Smartphone: Optimized for smartphones, this crawler emulates mobile browsing experiences to ensure accurate indexing for mobile users.
AdSense: With a mobile-centric focus, this bot scans web pages for AdSense advertisements tailored explicitly for mobile devices.
Mobile Apps Android: Specializing in Android applications, this crawler navigates the digital landscape to index and enhance app-related content.
Google Read Aloud: This unique bot caters to users with visual impairments by using text-to-speech technology to read web content aloud.
Feedfetcher: Dedicated to gathering and processing RSS and Atom feeds, this crawler ensures the timely delivery of syndicated content.
Google Favicon: Tasked with fetching and indexing website favicons, this bot adds a touch of visual flair to search engine results.
Duplex on the web: advanced bot leverages artificial intelligence to interact with web pages and perform tasks on behalf of users, such as booking appointments or making reservations.
Google StoreBot: Focused on e-commerce, this bot scours the digital shelves of online stores, cataloging products and facilitating their discoverability.
Web Light: This crawler optimizes web pages for low-bandwidth or slow internet connections, providing a faster and more accessible browsing experience.
As we dive into the intricate ecosystem of web crawlers, we uncover their diverse roles in shaping our search experiences, enhancing advertising strategies, and ensuring the dynamic and comprehensive indexing of the digital realm.
The Vital Role of Web Data Crawlers in SEO

Web data crawlers play a crucial role in the world of search engine optimization (SEO), contributing significantly to the visibility and ranking of your content. Here\'s why web crawlers are essential for SEO:
Indexing Content: Search engines like Google rely on web crawlers to discover, crawl, and index web pages. When a crawler visits your website, it analyzes the content, keywords, and structure of your pages. This information is then used by search engines to determine how relevant and valuable your content is for specific search queries. Without crawling, your content may remain invisible to search engines, resulting in poor visibility in search results.
Improved Visibility: Web crawlers ensure that your website\'s pages are included in search engine indexes. This increases the chances of your content appearing in search results when users search for relevant keywords or phrases. By optimizing your website for crawler accessibility, you enhance the visibility of your content, making it more likely to attract organic traffic.
Content Updates: As web crawlers revisit your website periodically, they detect updates and changes made to your content. This enables search engines to provide users with the most up-to-date and relevant information in search results. Regularly updated content signals to search engines that your website is active and valuable, contributing to improved SEO performance.
Competitive Analysis: Web crawling goes beyond SEO optimization. It is also employed by eCommerce sites to crawl competitors\' websites, analyzing product selection, pricing, and other relevant data. This practice, known as web scraping, provides valuable insights for market research, competitor analysis, and strategic decision-making.
SERP Data Collection: Web crawling is utilized by SERP API tools that crawl and scrape search engine results pages (SERPs). These tools extract data such as rankings, featured snippets, ads, and other SERP features. This information aids SEO professionals in monitoring and analyzing their website\'s performance in search results, identifying opportunities, and optimizing their strategies accordingly.
Navigating the Hurdles: Challenges Confronting Web Crawlers

Web crawlers, despite their remarkable capabilities, encounter various obstacles in their quest to explore the vast digital landscape. Here are some common challenges faced by web crawlers:
Robots.txt Restrictions: Websites utilize the robots.txt file to define what sections of their site should be crawled or excluded. While reputable web crawlers adhere to these restrictions, some may disregard them, potentially leading to restricted access to certain web pages or encountering submission limits imposed by the website.
IP Bans: To safeguard against malicious activity, websites may implement measures to ban specific IP addresses. This can affect web crawlers, especially those utilizing proxies or data center IP addresses commonly associated with fraudulent activities or scraping attempts.
Geolocation Restrictions: Certain websites may enforce geolocation-based restrictions, limiting access to content based on the visitor\'s geographic location. Overcoming such restrictions often requires the use of residential proxy networks to emulate specific locations and gain access to region-restricted content.
CAPTCHAs: Websites may deploy CAPTCHAs as a defense mechanism against suspicious activity or excessive requests from bots. CAPTCHAs present challenges for web crawlers as they are designed to verify human interaction, potentially disrupting the crawling process. Advanced web scraping solutions incorporate tools and technologies to overcome CAPTCHAs, including CAPTCHA-solving solutions.
These challenges necessitate adaptive strategies and solutions for web crawlers to ensure effective data collection and indexing while respecting website policies and security measures. Overcoming these hurdles enhances the crawler\'s ability to gather comprehensive data and provide valuable insights for various applications, including search engine optimization, market research, and data analysis.
Conclusion
Web crawlers are indispensable components of the internet ecosystem, serving as the backbone for search engines and enabling the seamless delivery of search results to users. They play a pivotal role in collecting and indexing data, facilitating efficient information retrieval and shaping the online experience. Additionally, web crawlers are valuable assets for companies and researchers seeking targeted data from specific websites.
While search engines rely on web crawlers to gather data across the web, there are instances where businesses and researchers require focused data extraction from particular sites, such as e-commerce platforms or listings websites. In such cases, specialized tools like Actowiz Solutions\' Web Scraper IDE offer tailored solutions, catering to specific research needs and providing enhanced data collection capabilities.
Web crawlers, with their widespread impact and versatile applications, continue to shape the digital landscape, empowering businesses, researchers, and users with comprehensive and relevant information. Their continuous evolution and adaptation to overcome challenges ensure that the internet remains a vast repository of knowledge and a gateway to endless possibilities.
Contact Actowiz Solutions now for additional information! We are here to assist you with your mobile app scraping, web scraping, and instant data scraper service needs. Don\'t hesitate to reach out to us today.
SOURCES >> https://www.actowizsolutions.com/unraveling-secrets-of-automated-data-exploration-and-web-crawler.php