Scrape Product Data Collection from WildBerries: A Step-by-Step Guide

Introduction
In the fast-paced realm of e-commerce, where dynamic markets and shifting consumer trends dictate success, reliable Ecommerce Data Scraping is the cornerstone for informed decision-making. Market research, pricing analysis, and strategic planning all hinge on harnessing comprehensive and up-to-date information about a diverse range of products. This is where WildBerries, a leading online marketplace, emerges as a goldmine of valuable product data.
WildBerries’s extensive catalog and diverse product offerings are an invaluable resource for businesses seeking a competitive edge. As one of the prominent players in the e-commerce landscape, it hosts a myriad of products spanning various categories – from fashion and electronics to home goods and beyond. For companies aiming to refine their market positioning, optimize pricing strategies, or gain insights into consumer preferences, tapping into the wealth of data provided by WildBerries becomes a strategic imperative.
In this digital age, where every byte of information holds potential, Actowiz Solutions brings forth a solution-oriented approach to empower businesses. Our expertise lies in navigating the complexities of Web Scraping Ecommerce Website Data to extract and harness the wealth of data offered by platforms like WildBerries. Join us on a journey where we scrape product data collection from WildBerries, providing actionable insights that drive your business toward success in the ever-evolving e-commerce landscape.
Understanding Web Scraping
Web scraping, a transformative technology in data collection, refers to the automated process of extracting information from websites. It allows individuals and businesses to efficiently aggregate, analyze, and interpret vast amounts of data. Actowiz Solutions aims to shed light on its relevance in modern data-driven practices in the context of understanding and harnessing the power of Ecommerce Data Scraping.
The significance of Ecommerce Data Scraping lies in its ability to democratize access to valuable data across the internet. For market researchers, businesses, and analysts, it is a pivotal tool for gathering real-time insights, tracking market trends, and staying ahead of the competition. In the context of Actowiz Solutions, where precision and efficiency meet innovation, web scraping becomes a key enabler for providing clients with tailored data solutions.
However, the utility of web scraping is accompanied by important legal and ethical considerations. While the technology is neutral, its application can sometimes infringe on a website’s terms of service. Actowiz Solutions places a strong emphasis on responsible and ethical web scraping practices. Our approach aligns with legal guidelines and ethical standards, ensuring that data extraction is conducted to respect the rights and policies of the data source. In this way, Actowiz Solutions leverages cutting-edge technology and champions a moral and conscientious approach to data acquisition.
Preliminary Steps
Before embarking on any web scraping endeavor, it is crucial to meticulously review and comprehend the terms of service of the target website, in this case, WildBerries. Examining WildBerries’ policies will provide essential insights into the permissibility and restrictions of web scraping activities.
The terms of service typically outline the website’s stance on data extraction, automated access, and the use of bots. WildBerries may explicitly prohibit or restrict web scraping activities to protect its content and infrastructure. It is essential to respect these guidelines to ensure ethical and legal compliance.
Regarding selecting a programming language to scrape product data collection from WildBerries, Actowiz Solutions recommends Python for its versatility, robust libraries, and community support in web scraping. Python offers libraries such as BeautifulSoup and Scrapy, which easily facilitate the extraction of data from HTML documents. Additionally, Python’s readability and simplicity make it an ideal choice for individuals and businesses seeking an efficient and robust solution for web scraping tasks.
Actowiz Solutions is adept at navigating the intricacies of Ecommerce Data Scraping within the bounds of legal and ethical considerations. Our expertise in Python ensures that the scraping process is effective and aligns with industry best practices and the policies outlined by websites like WildBerries.
Setting up Your Environment
To kickstart your Ecommerce Data Scraping project efficiently, it’s essential to set up the necessary tools and libraries while ensuring a clean and organized development environment. Actowiz Solutions recommends using Python and creating a virtual environment for managing dependencies.
Begin by installing Python on your system if you haven’t already. Once Python is installed, open your terminal and create a virtual environment using the following commands:

With the virtual environment activated, install the required libraries. For basic web scraping, BeautifulSoup is excellent for parsing HTML, while Selenium is handy for dealing with dynamic content. Use the following commands:

These commands install the necessary tools to fetch and parse web content efficiently. Remember to periodically check for updates to these libraries to ensure you have the latest features and bug fixes.
Actowiz Solutions specializes in creating robust Ecommerce Data Scraping solutions, utilizing the best tools and practices. By setting up a virtual environment and installing the required libraries, you establish a solid foundation for your scraping project, ensuring a systematic and organized approach to data extraction from websites like WildBerries.
Inspecting the WildBerries Website
Inspecting the structure of the WildBerries website is a crucial step in understanding how to extract the desired product data. Browser developer tools provide a comprehensive view of the website’s HTML, CSS, and JavaScript, allowing you to identify the relevant elements for web scraping.
Using Browser Developer Tools:
Open the Website:
Visit the WildBerries website using your preferred web browser
Access Developer Tools:
Right-click on the webpage and select “Inspect” or “Inspect Element” from the context menu. Alternatively, press Ctrl+Shift+I (Windows/Linux) or Cmd+Option+I (Mac) to open the Developer Tools.
Navigate to the Elements Tab:
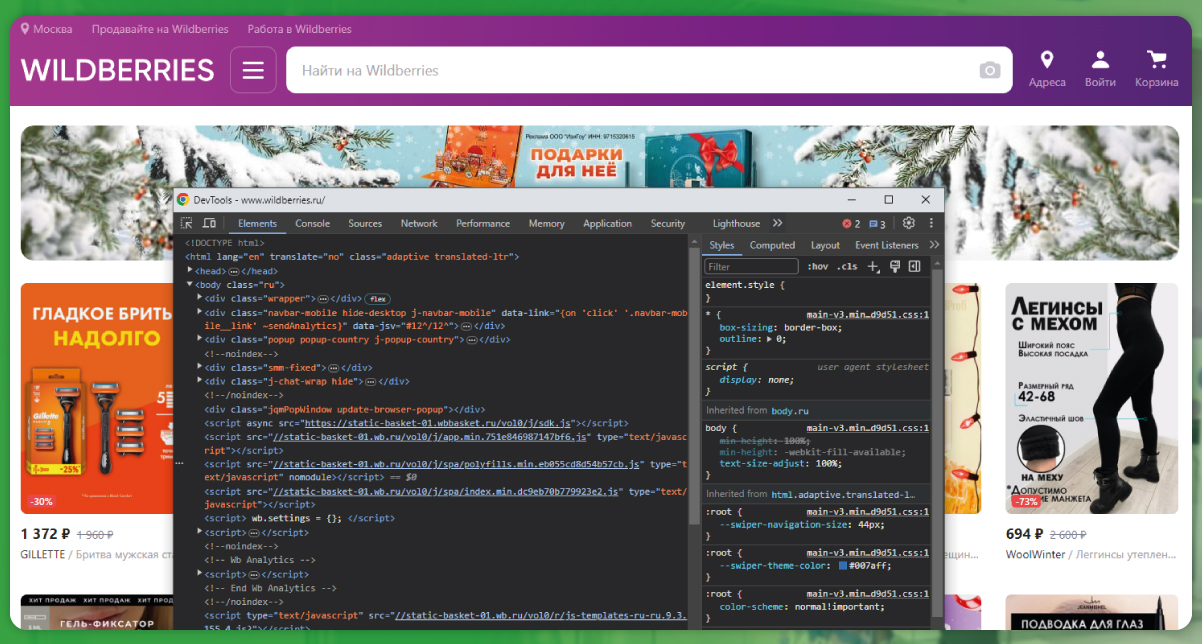
Within the Developer Tools, navigate to the “Elements” tab. This section displays the HTML structure of the webpage.
Locate Product Data Elements:
Use the cursor icon (usually represented by an arrow) to hover over different parts of the webpage. As you do so, the corresponding HTML code will be highlighted, helping you identify the structure.
Identify Relevant HTML Elements:
Look for HTML elements that contain the desired product data. Common elements include < div >, < span >, < ul >, and < li >. Pay attention to class names, IDs, or other attributes that distinguish these elements.
For example, product details like name, price, and description might be contained within specific < div > elements with unique identifiers.
By understanding the WildBerries website’s structure through developer tools, you can pinpoint the HTML elements that house the information you want to scrape. This knowledge will be essential when crafting your web scraper to target and extract the relevant data accurately. Actowiz Solutions ensures that our Ecommerce Data Scraping methodologies are meticulously designed to navigate and interact with websites effectively, adhering to best practices and ethical guidelines.
Building the Scraper:
To build a simple WildBerries product data scraper for using Python, we’ll leverage the requests library for sending HTTP requests and BeautifulSoup for parsing HTML. In this example, we’ll demonstrate how to retrieve the HTML content of the WildBerries website and use CSS selectors to locate and extract product data.
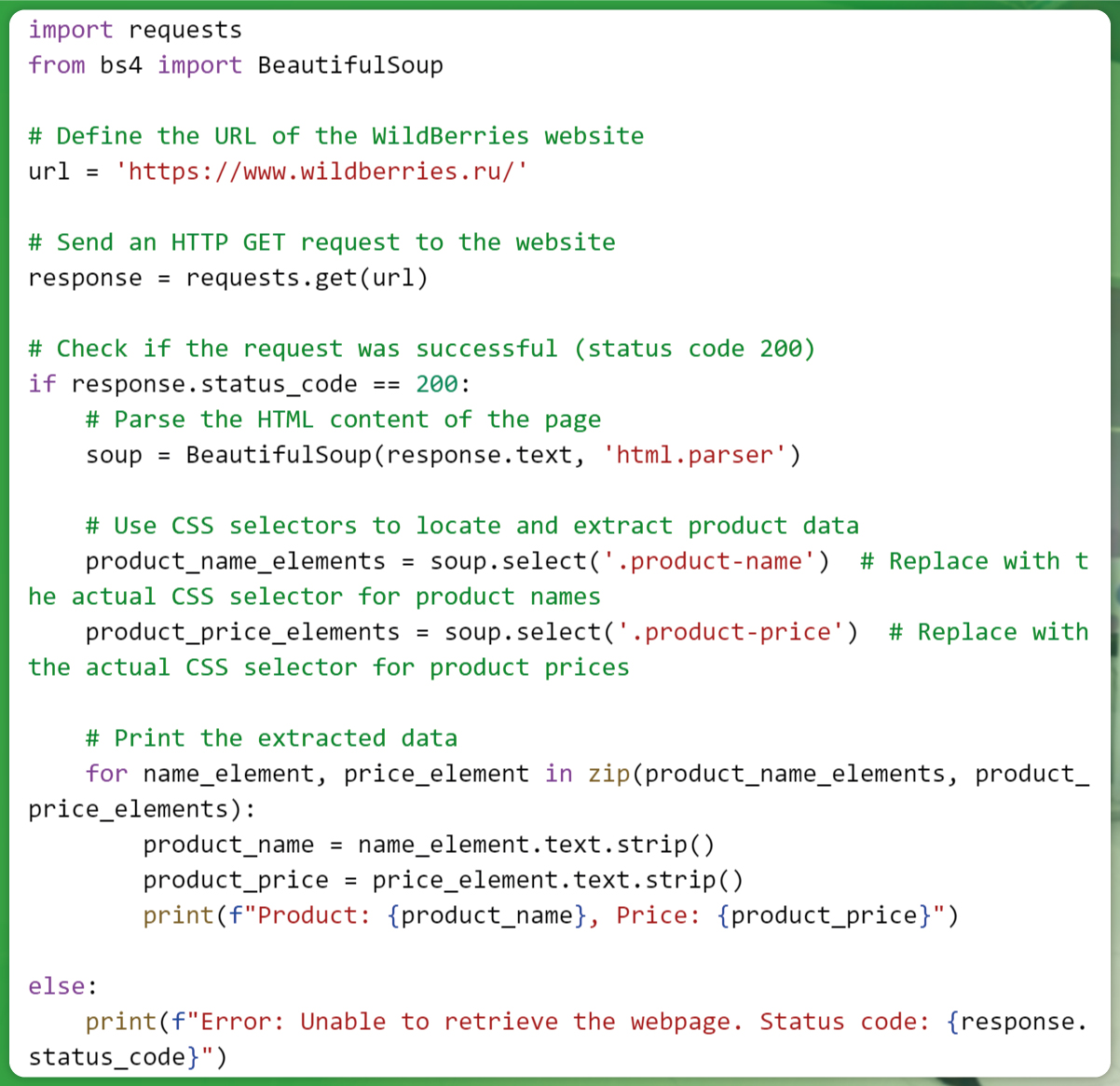
In this example, we use the requests library to send an HTTP GET request to the WildBerries website. We then parse the HTML content of the page using BeautifulSoup. The CSS selectors (e.g., ‘.product-name’ and ‘.product-price’) are used to locate specific HTML elements containing product names and prices.
Actowiz Solutions ensures that our Ecommerce Data Scraping methodologies are not only effective but also ethical and compliant with best practices. It’s important to note that website structures can change, so CSS selectors might need adjustment based on the current structure of WildBerries. Always respect the website’s terms of service and avoid sending too many requests to prevent IP blocking.
Data Parsing and Cleaning
After scraping the HTML content from WildBerries, the next crucial step is parsing the data and preparing it for analysis. Using Python and BeautifulSoup, Actowiz Solutions employs effective methods for parsing and cleaning the extracted information.
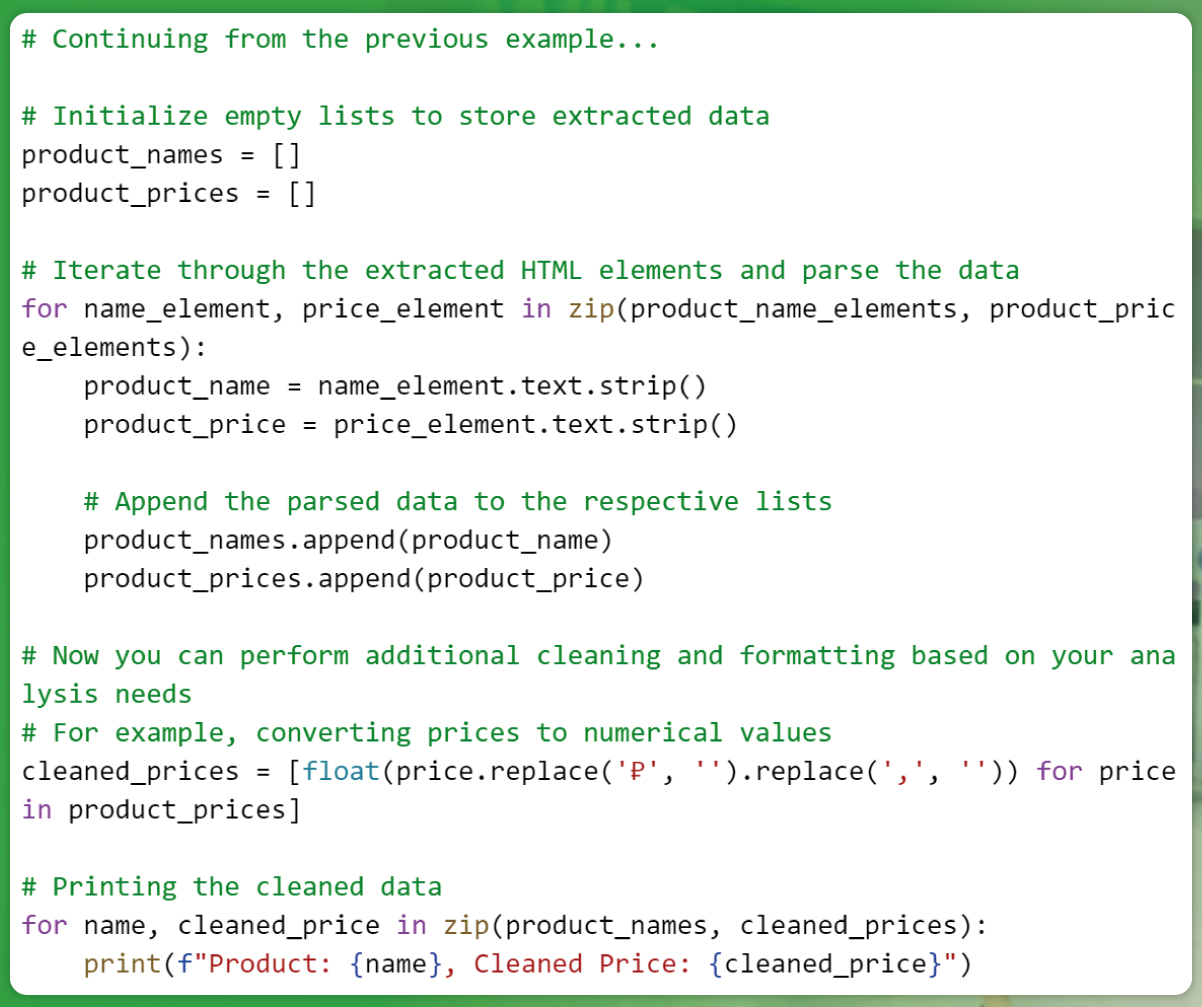
In this snippet, we parse the product names and prices from the HTML elements and store them in separate lists. Then, for further analysis, we clean and format the data. In this case, we remove the currency symbol ‘₽’ and commas from the prices and convert them to numerical values. This cleaned data is then ready for various analytical processes.
Actowiz Solutions emphasizes the importance of tailored Ecommerce Data Scraping strategies based on the specific requirements of your project. Whether it involves handling missing values, removing duplicates, or converting data types, our approach ensures that the extracted information is refined and ready for meaningful analysis.
Saving the Data
Once you’ve successfully extracted and cleaned the product data from WildBerries, it’s essential to store it in a structured format for future analysis and reference. Actowiz Solutions recommends saving the collected data in common formats such as CSV or JSON, or consider utilizing a database for more sophisticated data management.
Storing Data in CSV
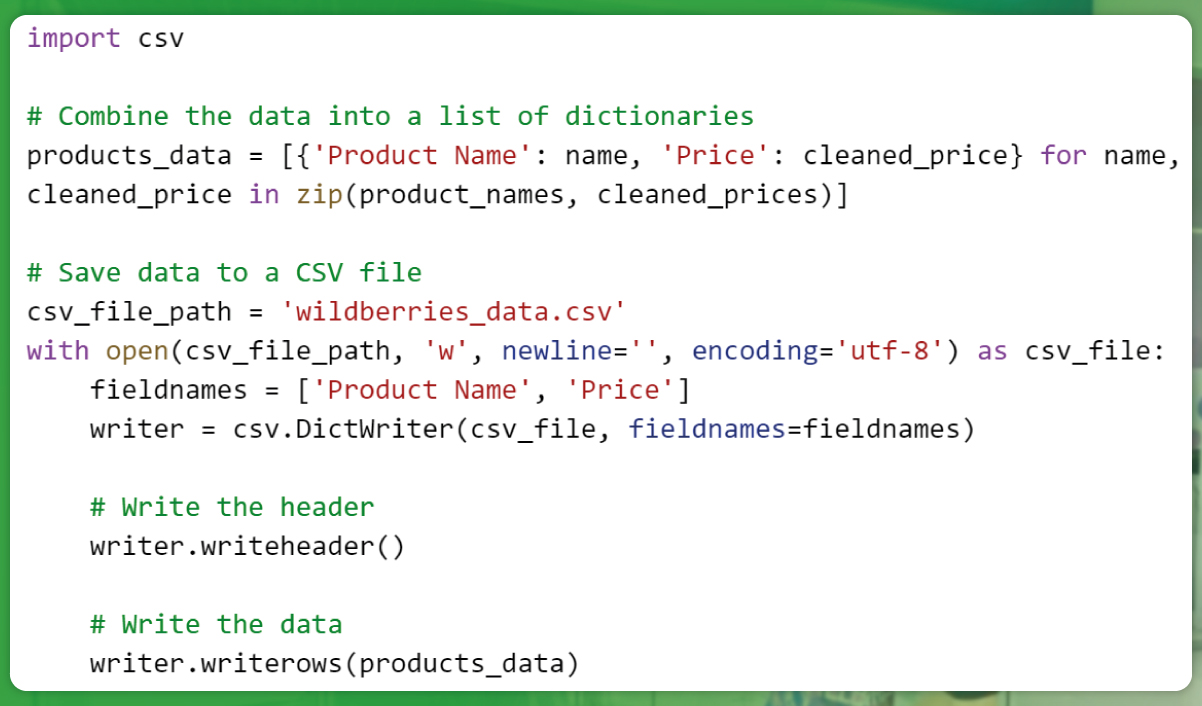
Considerations for Data Storage and Management:
File Formats: Choose a file format based on your data structure and future requirements. CSV is lightweight and widely supported, while JSON is suitable for nested or semi-structured data.
Database Integration: For larger datasets or ongoing scraping, consider using a database (e.g., SQLite, PostgreSQL) for efficient data storage and retrieval. Python’s SQLAlchemy library can assist in database management.
Automated Backups: Regularly back up your collected data to prevent loss in case of unexpected events. This ensures data integrity and availability for analysis.
Data Security: If dealing with sensitive data, implement security measures to protect it from unauthorized access. Encryption and secure access controls are essential components.
By adhering to these considerations, Actowiz Solutions ensures that data storage and management practices align with industry standards, promoting accessibility, security, and reliability in the handling of collected information.
Avoiding Detection and IP Blocking
To avoid detection as a scraper and prevent potential IP blocking, Actowiz Solutions employs several strategies that prioritize responsible and ethical web scraping practices.
User-Agent Headers: Set a user-agent header in your HTTP requests to mimic legitimate browser behavior. This helps prevent websites from identifying your requests as automated scripts. However, it’s essential to check and use the website’s accepted user-agent strings.

Randomize Request Timing: Introduce delays between your requests to mimic human behavior. This helps distribute the load and reduces the likelihood of triggering rate limits or being flagged as a scraper.

IP Rotation: If possible, rotate IP addresses to avoid being identified based on a single IP. This can be achieved using a proxy server or a rotating proxy service.
Use Robots.txt: Adhere to the rules specified in a website’s robots.txt file. This file provides guidelines on which parts of the site can or cannot be scraped. Respecting these rules is crucial for maintaining ethical scraping practices.
By implementing these strategies, Actowiz Solutions ensures that web scraping activities are conducted responsibly, minimizing the risk of detection and potential IP blocking. Respecting the website’s access policies is paramount, fostering a positive relationship with the website and safeguarding the integrity of the scraping process.
Testing and Debugging
Actowiz Solutions strongly advocates for thorough testing and debugging practices to ensure the reliability and effectiveness of your web scraper. Before deploying your scraper on a larger dataset, consider the following tips:
Test on a Small Scale: Begin by scraping a small subset of data to identify potential issues before scaling up. This allows you to refine your code and ensures that the scraper behaves as expected.
Monitor Console Output: Print relevant information to the console during testing. This helps you track the progress of your scraper and identify any unexpected behavior.
Use Logging: Implement logging to record detailed information about the scraping process. Log entries can be invaluable for diagnosing issues and understanding the flow of your program.
Handle Exceptions: Anticipate potential errors and exceptions that may arise during scraping. Implement robust error-handling mechanisms to gracefully handle unexpected situations and prevent your scraper from crashing.
Inspect HTML Changes: Websites may undergo updates or changes in structure. Regularly inspect the HTML structure of the target site to ensure that your selectors and scraping logic remain accurate.
Utilize Breakpoints: If using an integrated development environment (IDE), set breakpoints strategically in your code to pause execution. This allows you to inspect variable values and step through the code, facilitating effective debugging.
By diligently testing and debugging your web scraper, Actowiz Solutions ensures the development of a reliable tool that delivers accurate and consistent results. This proactive approach minimizes the risk of errors, streamlines the scraping process, and contributes to the overall success of your data collection efforts.
Conclusion
Extracting product data from WildBerries involves key steps: understanding web scraping, inspecting the website, building a scraper, parsing and cleaning data, saving it in a structured format, and implementing strategies to avoid detection. Actowiz Solutions encourages users to follow ethical guidelines, respecting website policies to prevent IP blocking. Our expertise ensures responsible and effective web scraping solutions. Actowiz – Empowering data-driven decisions. Contact us for tailored Ecommerce Data Scraping solutions that elevate your business insights and strategies. You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
SOURCES >> https://www.actowizsolutions.com/scrape-product-data-collection-from-wildberries.php
Tag : #WildBerriesProductDataScraper
#WildBerriesProductDataScraping
#EcommerceDataScraping
#EcommerceDataCollection
#WildBerriesProductDataCollection
#WebScrapingEcommerceWebsiteData