Multi Curl Web Scraper for Price Comparison

Introduction
In today’s bustling online marketplace, consumers are often overwhelmed by the plethora of options available for their needs. Whether it’s purchasing a car, finding the best deals on electronics, or simply comparing prices across various platforms, having access to accurate and up-to-date data is crucial. This is where web scraping services come into play, offering a powerful solution for gathering information from multiple websites simultaneously. In this blog post, we’ll delve into the intricacies of building a Multi Curl web scraper, focusing on efficiency, speed, and reliability.
Understanding the Requirement
Imagine a platform designed to cater to consumer needs by providing comprehensive price comparison and deal-hunting services. At the heart of this platform lies a robust data collection mechanism – the web scraper. The goal is simple yet challenging: scrape data from 10 different websites, translate it into a unified format, and store it in a MongoDB database. What sets this project apart is the requirement for real-time data updates, akin to the seamless operation of websites like travelfox.com.
Choosing the Right Tools
To tackle this project effectively, we have two main options: Java multithreading or Python with Scrapy. While both approaches have their merits, we’ll opt for Python and Scrapy due to its ease of use, extensive library support, and robust ecosystem for web scraping services. Additionally, Python’s asynchronous capabilities will prove invaluable for concurrent scraping operations, aligning perfectly with the project’s requirement for speed and efficiency.
What are the Benefits of Building a Multi Curl Web Scraper?
Building a Multi Curl web scraper offers a multitude of benefits, especially when it comes to tasks like price comparison across various websites. Here are some key advantages:
Efficiency: Multi Curl web scraping allows for simultaneous data extraction from multiple websites. This means you can gather information from different sources concurrently, significantly reducing the time it takes to collect data compared to sequential scraping methods. As a result, you can provide users with up-to-date and comprehensive price comparison results in a fraction of the time.
Speed: By leveraging asynchronous requests and parallel processing, Multi Curl web scraping can dramatically increase scraping speed. This is particularly advantageous when dealing with large volumes of data or when real-time updates are required, as it ensures that the scraper can keep up with the rapid pace of the web.
Accuracy: With data being collected from multiple sources simultaneously, Multi Curl web scraping helps ensure the accuracy and completeness of the information gathered. By cross-referencing data from different websites, you can identify discrepancies or outliers more easily and ensure that the final dataset is reliable and comprehensive.
Scalability: Multi Curl web scrapers are inherently scalable, allowing you to easily expand your scraping operations to include additional websites or sources as needed. Whether you’re adding new categories for price comparison or scaling up to handle increased user demand, the architecture of a Multi Curl scraper can accommodate growth without sacrificing performance.
Resource Optimization: Unlike traditional scraping methods that may consume excessive memory or CPU resources, Multi Curl web scraping is designed to be resource-efficient. By making efficient use of network connections and system resources, you can minimize the impact on server infrastructure and ensure smooth operation even under heavy loads.
Real-Time Updates: One of the key advantages of Multi Curl web scraping is its ability to provide real-time updates. By continuously monitoring multiple websites and fetching new data as it becomes available, you can ensure that your price comparison results are always current and reflect the latest changes in pricing and availability.
Competitive Advantage: In today’s fast-paced online marketplace, having access to timely and accurate pricing information can give you a significant competitive advantage. By building multi curl web scraping APIs, you can stay ahead of the competition by offering users the most comprehensive and up-to-date price comparison services available.
Building a Multi Curl web scraper for price comparison offers numerous benefits, including increased efficiency, speed, accuracy, scalability, resource optimization, real-time updates, and a competitive edge. Whether you’re developing a price comparison platform, conducting market research, or optimizing your e-commerce operations, multi curl web scraping APIs can help you gather the data you need quickly, reliably, and cost-effectively.
Building the Multi Curl Web Scraper
Step 1: Setting Up the Environment
Before diving into the code, ensure you have Python and Scrapy installed on your system. Once done, create a new Scrapy project using the command-line interface:
scrapy startproject price_comparisonStep 2: Defining Spider Classes
In Scrapy, spiders are the core components responsible for crawling websites and extracting data. For our multi-site scraping task, we’ll create separate spider classes for each website, leveraging the power of Scrapy’s asynchronous processing.
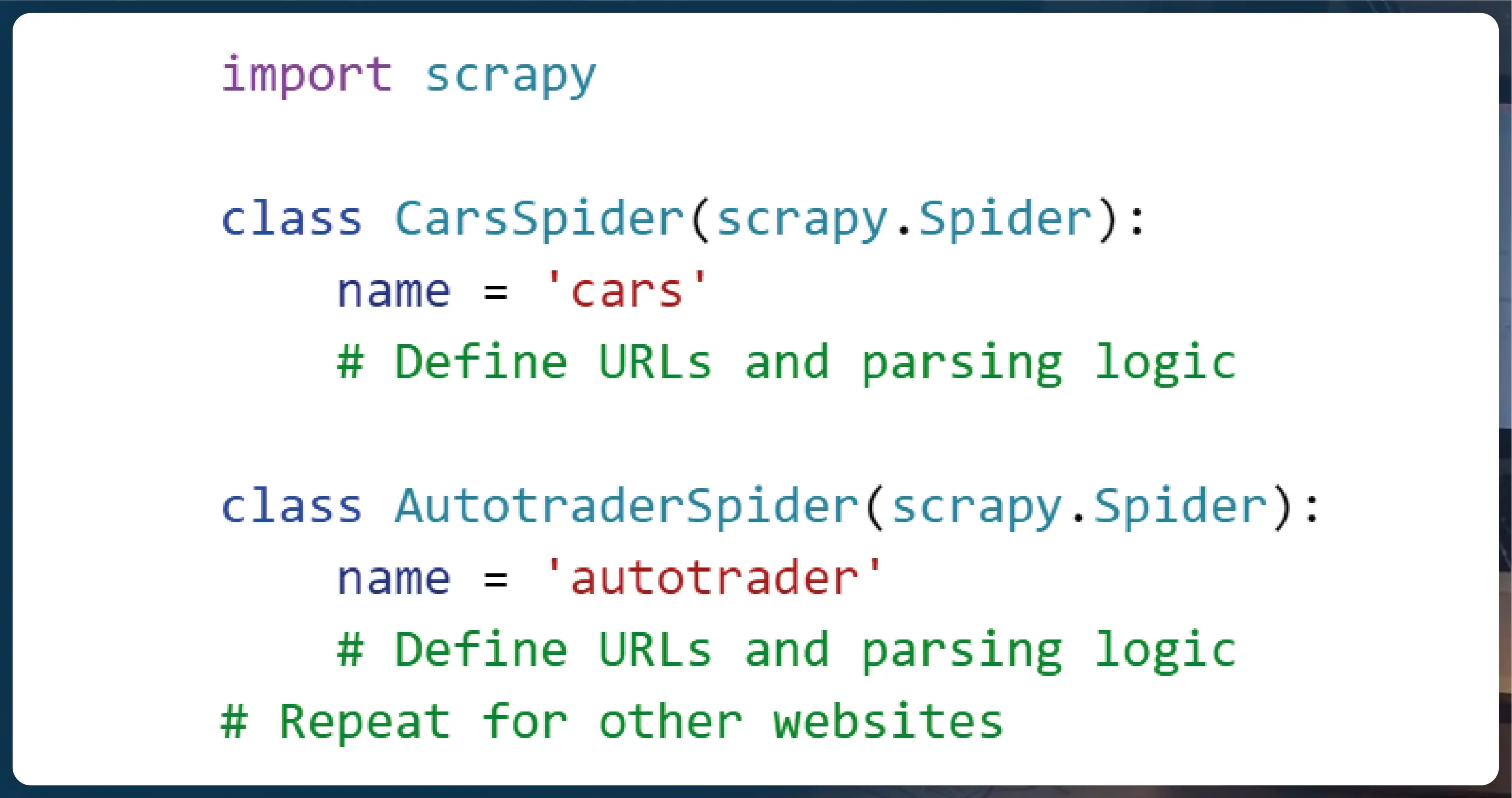
Step 3: Implementing Asynchronous Requests with Multi Curl
To achieve concurrent scraping across multiple websites, we’ll utilize Python’s asyncio library along with Scrapy’s asynchronous features. By employing asyncio’s event loop and coroutine-based syntax, we can send requests to each website concurrently, significantly boosting scraping speed.
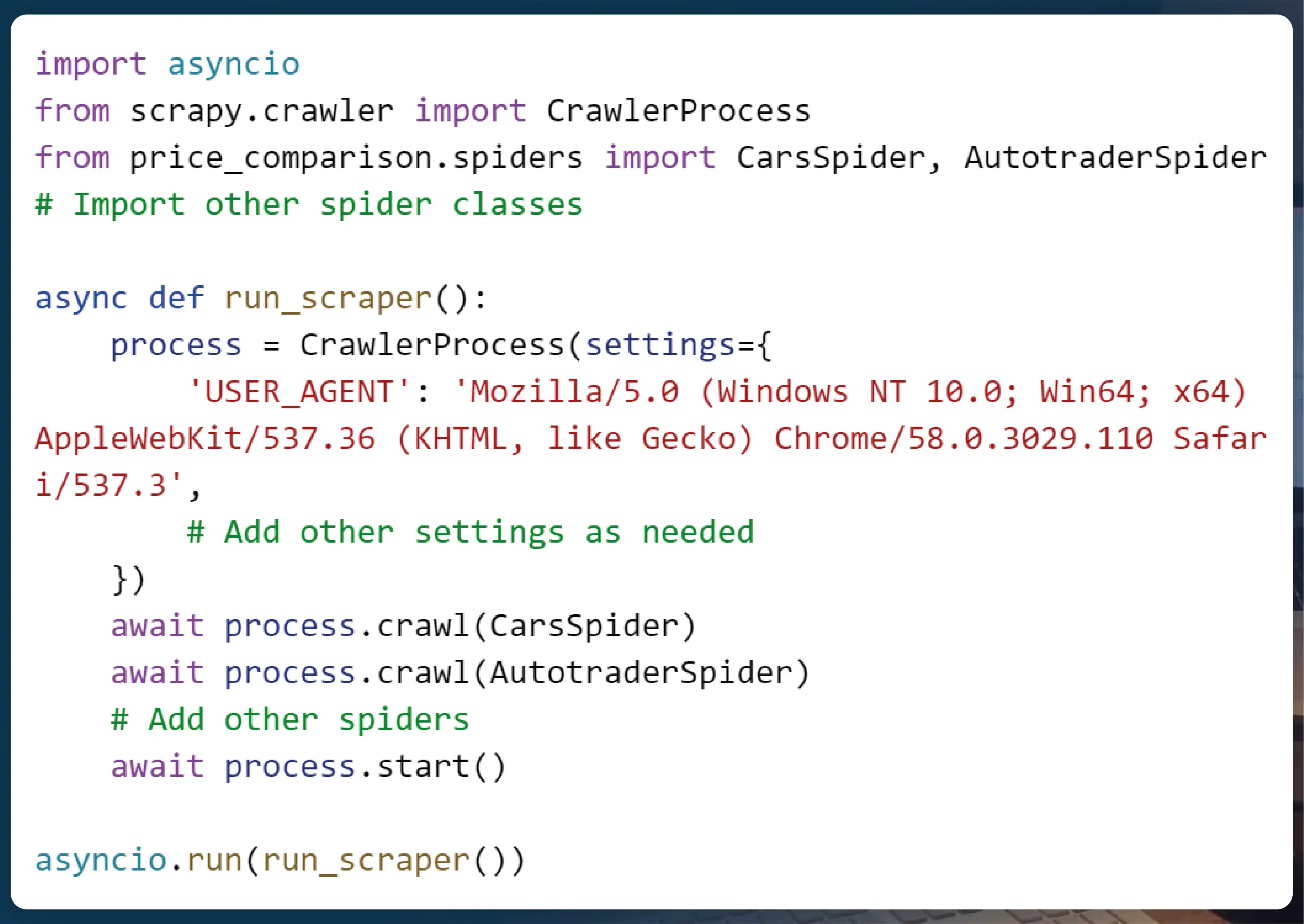
Step 4: Optimizing Speed and Space
To ensure optimal performance, it’s essential to fine-tune our multi curl web scraping APIs for speed and efficiency. This includes implementing techniques such as request throttling, response caching, and minimizing memory usage. Additionally, leveraging Scrapy’s built-in features like parallel processing and request prioritization can further enhance scraping speed while conserving system resources.
Conclusion
Developing a Multi Curl web scraper for price comparison presents both challenges and opportunities. Harnessing Python, Scrapy, and asynchronous programming empowers us to construct a resilient scraping solution, swiftly collecting data from multiple websites in real-time. Whether it’s scrutinizing car prices, scouting electronics deals, or analyzing market trends, well-crafted multi curl web scraping APIs furnishes indispensable insights for consumers and businesses.
Elevate your data gathering capabilities with Actowiz Solutions. Whether you’re crafting a bespoke price comparison platform or amplifying existing operations, mastering web scraping services is a strategic investment. With Actowiz, unlock boundless potential in navigating the expansive realm of online data. Reach out today and seize the competitive advantage. You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
sources >> https://www.actowizsolutions.com/multi-curl-web-scraper-for-price-comparison.php
Tag : #MultiCurlWebScraping
#MultiCurlWebScraper
#MultiCurlWebScrapingApis
#MultiCurlWebDataExtraction
#MultiCurlWebDataCollection