How to Utilize Playwright Python for Scraping Musical Instruments Data from Amazon Today’s Deals?

Amazon is an e-commerce giant providing many products, including groceries and electronics. Its popular sections include “Today’s Deals,” which features limited-time discounts on different products, including all musical instruments. These discounts on different musical instruments may vary from some percentage points to over 50% off the primary prices. All deals cover categories like fashion, electronics, toys, and home goods.
Amazon offers an extensive selection of electronic and traditional musical instruments from leading manufacturers and brands. These may include electric and acoustic guitars, orchestral instruments, drums, keyboards, and accessories like stands, cases, and sheet music. In addition, the “Used & Collectible” section of Amazon allows customers to buy pre-owned instruments with discounted pricing.
This blog is a step-by-step guide about utilizing playwright Python to scrap musical instrument data from Amazon today’s deals and save that in the CSV file. We would be scraping the given data attributes from individual Amazon pages.
- Product Name
- Product URL
- Brand
- Color
- Compatible Devices
- Connectivity Technology
- Connector Type
- Material
- MRP
- Number of Reviews
- Offer Price
- Rating
- Size
Playwright Python
Here, we will use Playwright Python for scraping data. Playwright is an open-source tool to automate web browsing. Using Playwright, you could automate tasks like navigating to the web pages, filling forms, clicking buttons, and confirming that particular elements are shown on a page.
Among the main features of Playwright is its compatibility with different browsers like Firefox, Safari, and Chrome. So, you can make tests run on different browsers, ensuring better coverage and lowering the probability of compatibility difficulties. In addition, Playwright has in-built tools to handle common testing problems like waiting for elements to load, dealing with network errors, or debugging problems in a browser.
Another benefit of Playwright is that it cares about parallel testing, helps you do many tests concurrently, and significantly speeds up a test suite. It benefits complex or large test suites that can take longer to run. As a standby for present automation tools like Selenium, it has become well-associated for its performance, usability, and compatibility with front-line web technologies.
Let’s follow the step-by-step guide to using Playwright in Python to scrap
musical instrument data from Amazon Today’s Deals.
Import Necessary Libraries
To begin our procedure, we would need to import necessary libraries that will interrelate with the site and scrape the required information.

‘random’: You can use this library to generate random numbers that can be helpful to generate test data or randomize the test order.
‘asyncio’: You can use this library to handle asynchronous programming within Python, which is essential while using an asynchronous API of Playwright.
‘pandas’: You can use this library to do data analysis & manipulation. Here, it stores and operates data obtained from web pages getting tested.
‘async_playwright’: It is an asynchronous API for Playwright utilized in the script to automate browser testing. The asynchronous API helps you perform multiple operations that can make tests quicker and more effective.
You can use these libraries to automate browser testing with Playwright, including producing test data, dealing with asynchronous programming, saving and operating data, and automating browser interactions.
Product Links Scraping
Product link scraping is the procedure of gathering and organizing product URLs listed on web pages or online platforms.

Here we have used a Python function called ‘get_product_links’ for scraping resultant product links from a web page. This function is asynchronous, so it can wait for lengthy procedures and carry out numerous tasks without affecting key implementation strands. The function needs a single-page argument that is an example of a page in the Playwright. The function utilizes the ‘query_selector_all’ technique to choose all the elements on a resultant page that matches the particular CSS selector. A selector will recognize the elements which have product links. This function loops using every selected element and utilizes the ‘get_attribute’ technique to scrape the href attribute with product URLs. The scraped URL is added to an empty list called ‘product_links’ for storing the scraped links.
Data Extraction
Here, we will recognize required attributes from a Website and scrape Product Names, Total Reviews, Brands, Ratings, Offer Prices, Original Prices, and Information on every musical instrument.
Product Name Extraction
The product name extraction is a similar procedure to scraping product links. Our objective is to choose elements on every web page with detailed product names, and scrape text content from web pages.
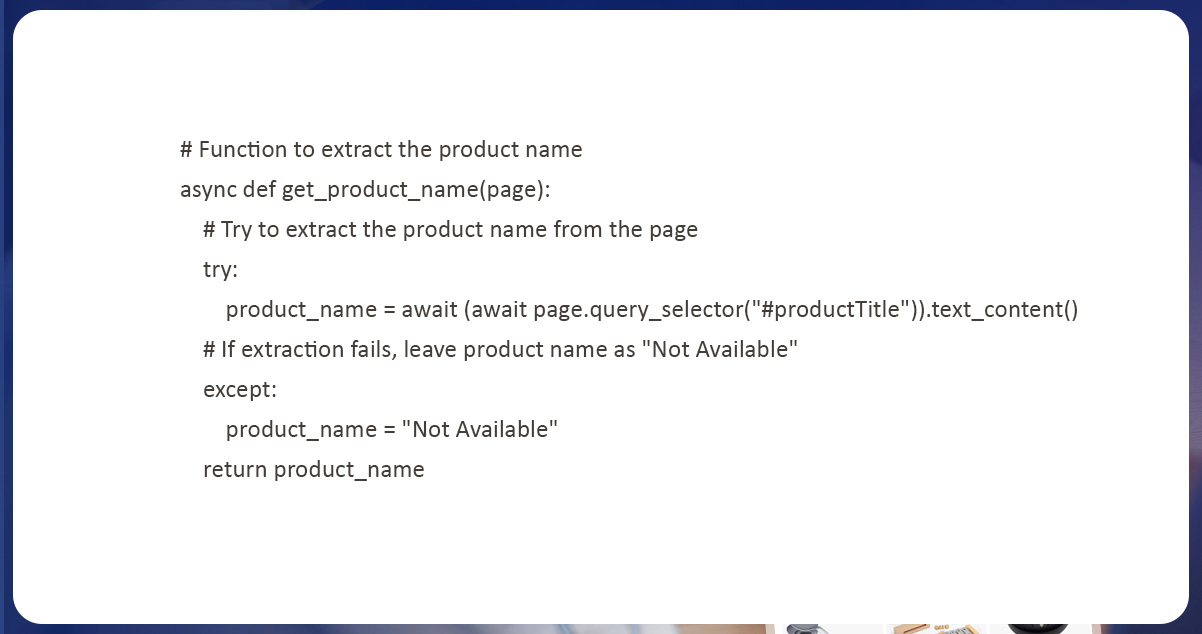
Here we have utilized an asynchronous function named ‘get_product_name’ to scrape product names from resultants’ web pages. This function utilizes the ‘text_content’ technique of selected elements to scrape products’ names from a page. This function utilizes a ‘query_selector’ technique to choose the elements on all pages which matches particular CSS selector and the function will identify the elements that contain a product name. A code uses an a’ try-except block to deal with errors that occur during extraction of product names from a page. If the function effectively scrapes the product name, it returns as the string. If data extraction fails, a function returns a product name like “Not Available,” which indicate that product names weren’t available on a page.
Product Brand Extraction
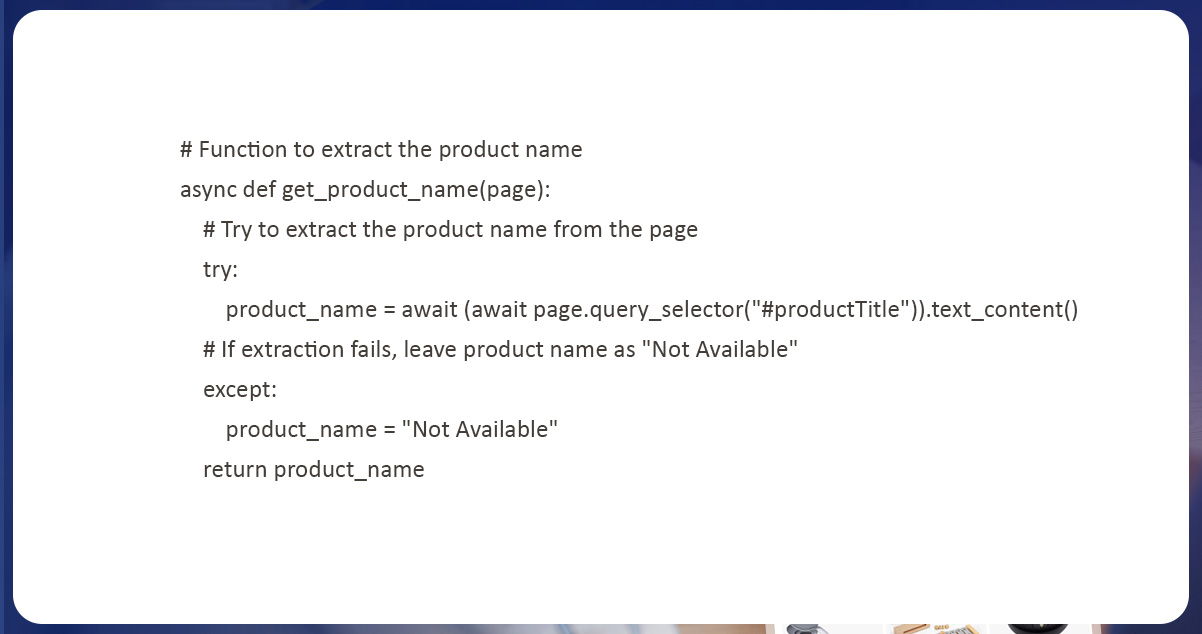
Correspondingly to the product name extraction, we have used an asynchronous function called ‘get_product_brand’ to scrape the corresponding product brand from a web page. This function utilizes a ‘query_selector’ technique to choose page elements matching a detailed CSS selector. The selector is used for identifying elements with a brand of complementary products.
After that, the function utilizes the ‘text_content’ technique of a selected element for scraping the brand name from a page. The code utilizes a try-except block to deal with the errors that occur during the brand extraction. If a product brand is successfully scraped, it returns like a string. In case the extraction fails, a function returns the “Not Available” string indicating that a brand of related products was unavailable on a page.
Correspondingly, we can scrape other attributes like MRP, total reviews, offer price, ratings, size, compatible devices, color, material, connector type, and connectivity technology. We can also use the same method we used in earlier steps to scrape other product features. For every attribute you wish to scrape, you can outline a function that utilizes a ‘query_selector’ technique to choose relevant elements on a page. You can also use the ‘text_content’ technique or a parallel method to scrape the anticipated data and also required to modify CSS selectors utilized in functions depending on the web page structure you are extracting.
Products MRP Extraction

Products Offer Price Extraction

Total Products Review Extraction

Products Ratings Extraction

Product Size Extraction

Products Colors Extraction

Products Material Extraction

Products Compatible Devices Extraction

Products Connectivity Technology Extraction

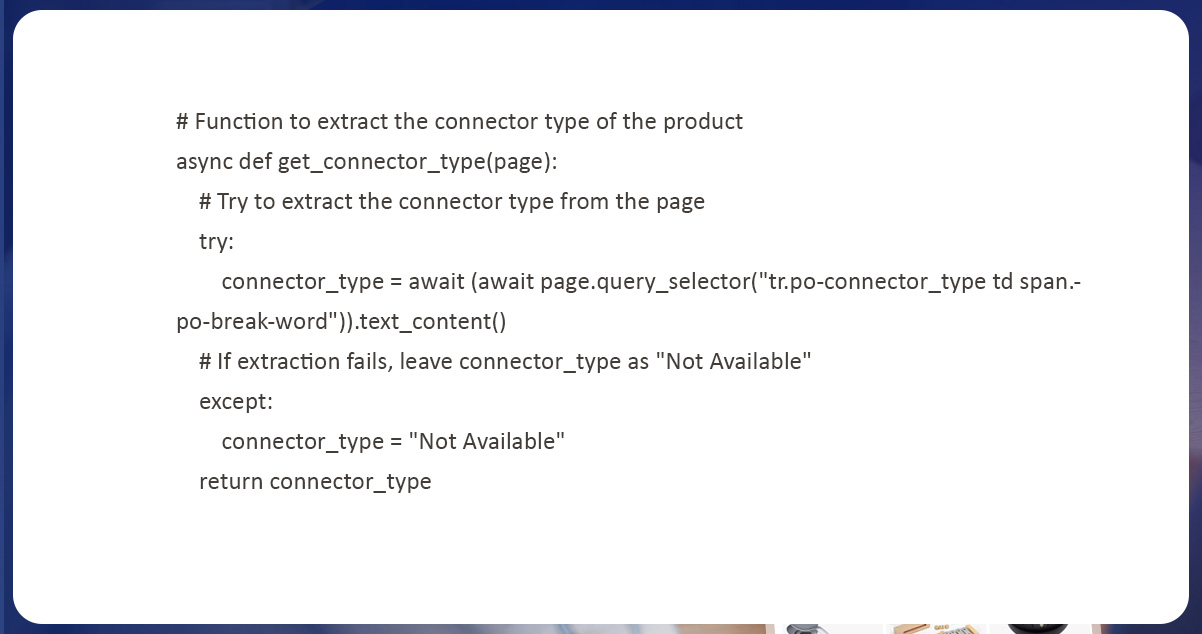
Products Connector Type Extraction
Request Retry Using Maximum Retry Limits
Request retry characteristic is vital of web extraction because it assists in handling unexpected responses and provisional network errors from a website. The objective is to send a request again in case it fails in the first time, increasing the probability of getting success.
Before URL navigation, the script applies a retry instrument if a request gets time out. This does that by utilizing an entire loop which keeps trying to direct the URL till a request thrives or maximum retries are reached. If maximum retries are reached, a script introduces an exception code. This code requests the provided link and retries a request in case it fails. This function is helpful while extracting web pages because, at times, requests might fail or time out because of network issues

Here function requests any specific links using the ‘goto’ technique of a page object from the Playwright library. While the request fails, a function tries that again at a given number of times. The maximum retries are defined by MAX_RETRIES continuous as 5 times. Between every retry, a function uses asyncio.sleep technique to wait for a random duration of 1-5 seconds. It is done to prevent the codes from quickly retrying a request, which might cause the requests to fail more often. The perform_request_with_retry function has two arguments: link and page. The page argument is a Playwright page object used for performing the requests; the link argument is a URL for which a request is made.
Product Data Saving Extraction
In the following step, we call functions and save data to the empty list.

We utilize an asynchronous function called ‘main,’ which scrapes product data from Amazon’s Today’s Deals page. This function is started by launching the new browser – chromium using Playwright. It opens a newer page in a browser. Then we navigate to Amazon’s Today’s Deals page with a perform_request_with_retry function. This function requests a link and retries request in case it fails, having a maximum of 5 retries. This ensures that a request to Amazon’s Today’s Deals page succeeds.
When a Deals page gets loaded, we scrape links to every product with the ‘get_product_links’ function well-defined in a script. After that, a scraper reiterates over every product link. After that, we load a product page with the ‘perform_request_with_retry function.’ The operation scrapes all the details and stores them like a tuple. A tuple makes a Pandas dataframe. A data frame gets exported to the CSV file with the to_csv technique of Pandas dataframe.
To finish, we call the ‘main’ Function:

The ‘asyncio.run(main())’ statement gets used to work the critical function like an asynchronous coroutine.
Conclusion
Extracting data from Today’s Deals section of Amazon could be a helpful method to collect information about different products getting provided at discounted prices. In the blog post, we explored using Playwright Python to scrap data from a musical instruments section in Today’s Deals on Amazon. If you follow the steps in the tutorial, you will quickly familiarize yourself with a code to extract data from different sections of the Amazon website or other sites.
However, it is very important to observe that web scraping is a controversial practice, and it might be prohibited by a site you are extracting from. Always check a website’s terms of service before trying to extract data from that, and respect all limitations or restrictions they might have placed.
Overall, web scraping can be a potent tool to gather data and automate tasks; however, you should use it ethically and sensibly. By following the best practices and respecting site policies, you could utilize web scraping for your benefit and get essential insights from the data you gather.
For more information, contact Actowiz Solutions now! You can also reach us for all your mobile app scraping and web scraping service requirements!
KNOW MORE : https://www.actowizsolutions.com/how-to-utilize-playwright-python-for-scraping-musical-instruments-data-from-amazon-todays-deals.php