


Introducing Threads, Meta\'s new microblogging platform provides valuable public data for sentiment analysis, market research, and brand awareness. This tutorial explores how to scrape Threads using Python with popular community packages. Let\'s dive in and learn how to create a Python scraper for Threads!
Note: Before proceeding, ensure you comply with Threads\' terms of service and any other relevant legal requirements regarding web scraping and data usage.
Why Scrape Data from Threads?
Threads is a rich, publicly available data source with immense value for various purposes. From conducting sentiment analysis for market research and brand awareness to identifying potential leads and monitoring public figures, the platform offers valuable information.
Since all the data on Threads is publicly accessible, scraping and utilizing it for research or analysis is legal and permissible. This allows researchers and analysts to harness the platform\'s data to gain insights, track trends, and draw meaningful conclusions to support their projects and objectives.
However, it\'s essential to always adhere to ethical practices and respect the platform\'s terms of service while scraping and using the data. Responsible data handling ensures that valuable resources like Threads remain available for the benefit of researchers, analysts, and the wider community.
Setup
To make the scraping process accessible for the dynamic JavaScript-based Threads application, we will utilize a headless browser. For this task, we have two excellent options: Playwright and ActoWiz-SDK. Additionally, we will use the jmespath library for parsing Threads data in JSON format. All of these packages can be installed easily using the pip command. Here\'s how:
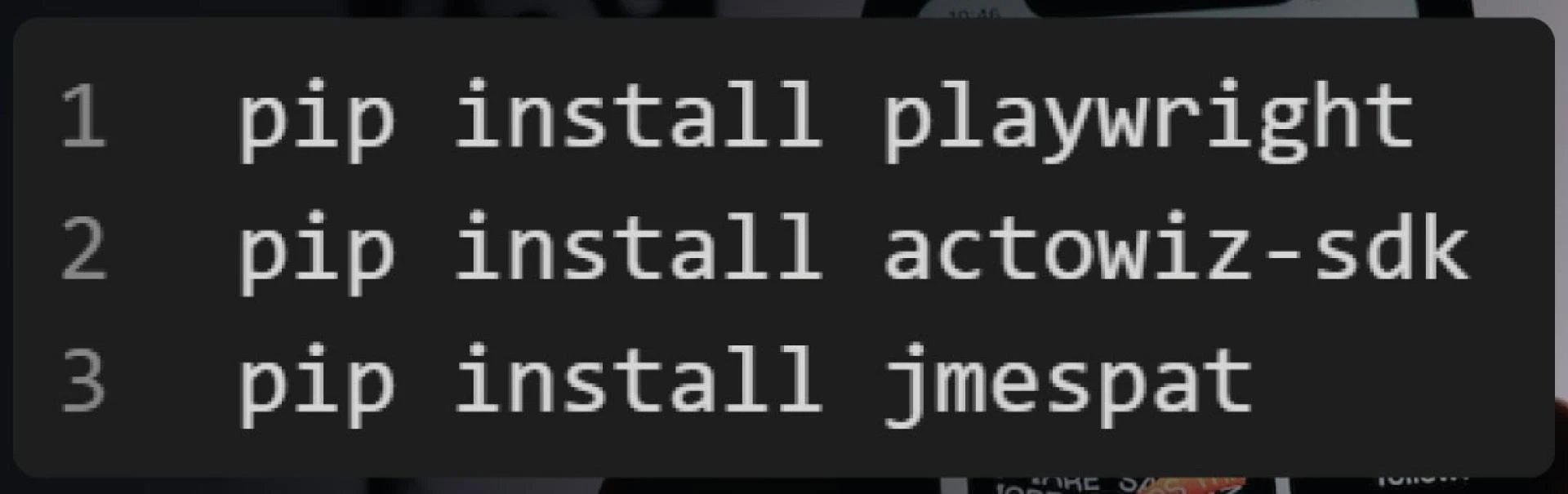
By incorporating Playwright or ActoWiz-SDK for headless browsing and jmespath for JSON parsing, we can effectively scrape and extract the valuable data from Threads\' dynamic JavaScript-driven pages. These tools will enable us to access and process the required information for our sentiment analysis, market research, brand awareness, lead generation, and other analytical needs. Remember to follow ethical guidelines and respect the platform\'s terms of service while conducting web scraping activities.
Scraping Threads Data (Posts)
To begin the thread scraping process on Threads, we first need to understand how our browser interacts with the platform when it loads a specific thread page, like "threads.net/t/CuVdfsNtmvh/". By inspecting the page using Chrome Developer Tools, we can observe that once the page is loaded, it makes a request to an "/api/graphql" endpoint to fetch the thread\'s data along with all its comments..
Unfortunately, reverse-engineering the complex and token-filled GraphQL call manually would be time-consuming and challenging. Instead, we can adopt a more efficient approach by utilizing background request capture with a headless browser.
By employing a headless browser, such as Playwright or ActoWiz-SDK, we can automate the process of loading the thread page, capturing the background requests made to the "/api/graphql" endpoint, and extracting the data we need from the responses. This method streamlines the scraping process and allows us to efficiently collect the desired thread and comment data from Threads without the need for manual reverse engineering.
The combination of a headless browser and background request capture will significantly simplify the thread scraping process and enable us to access the necessary data for our analysis and research purposes.
To scrape the large Threads datasets and reduce them to the most critical data fields, we will use Python with Playwright or ActoWiz-SDK. The process involves the following steps:
Open a Playwright-controlled Chromium browser.
Enable background request capture to intercept network requests.
Navigate to the Threads URL and wait for the page to load.
Extract the GraphQL responses from the captured background requests.
Extract the essential thread and comment data from the responses.
Parse the Threads data using the Jmespath JSON parsing library.
Using Playwright or ActoWiz-SDK in Python, we can efficiently automate this process to scrape Threads and focus on the critical information needed for analysis, research, and other applications.
Python
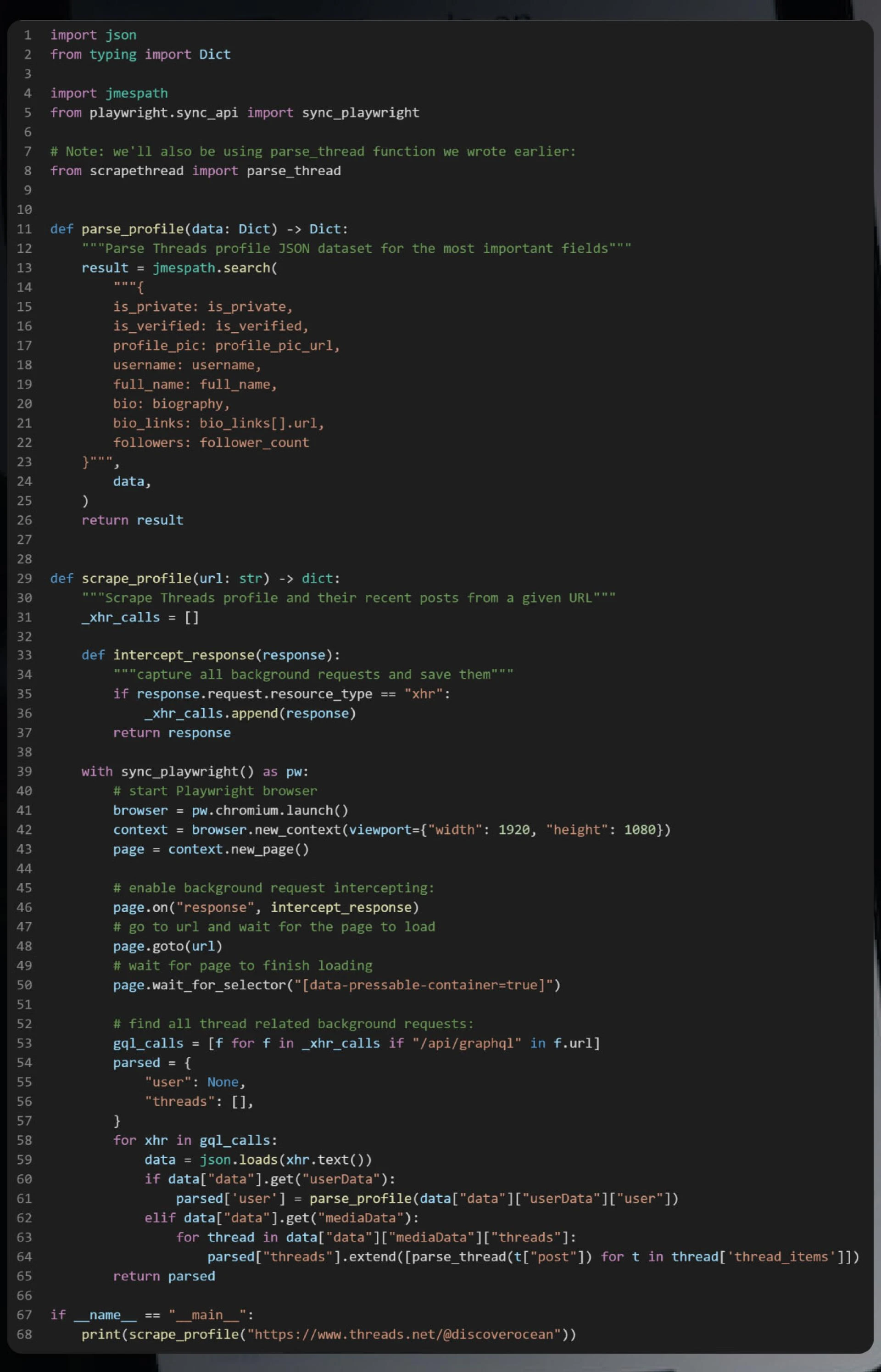
Above, as we began scraping Threads posts, we initiated a Playwright-controlled Chromium browser, established a connection to the page, and gathered background request data. This data includes all the pertinent Threads user information and their recent posts. Using the powerful jmespath JSON parsing library, we efficiently reduced this data to a single JSON object containing the most relevant and essential information from the scraped Threads datasets.
FAQ
Q: Are web scraping Threads legal?
A: Web scraping Threads or any website should be done in compliance with the website\'s terms of service and relevant legal regulations. Review and understand the website\'s policy on web scraping before proceeding.
Q: Can I scrape all public data from Threads without restrictions?
A: While Threads contains publicly available data, it\'s essential to check the website\'s robots.txt file and terms of service to understand any limitations on web scraping. Some websites may restrict the frequency of requests or the amount of data that can be scraped.
Q: How often can I scrape Threads data?
A: The scraping frequency should be respectful and considerate of the website\'s server resources. Excessive or aggressive scraping may lead to IP blocking or other measures to prevent misuse.
Q: Can I use the scraped Threads data for commercial purposes?
A: The usage of scraped data, including Threads data, for commercial purposes, may be subject to specific legal and ethical considerations. Always ensure you have proper authorization or rights to use the data commercially.
Q: Are there any API alternatives to web scraping Threads?
A: Threads may offer an official API for accessing data in a more structured and controlled manner. Check the website\'s documentation or contact the platform\'s support team for API availability.s
Q: How can I avoid IP blocking while scraping Threads?
A: To avoid IP blocking, consider implementing rate-limiting, rotating proxies, and respecting the website\'s guidelines on scraping frequency and request limits.
Q: Should I notify Threads before scraping their data?
A: While only sometimes required, it is considered good practice to notify the website\'s administrators about your intent to scrape their data. This can foster a positive relationship and ensure you comply with their terms of service.
Q: What are the common challenges in web scraping Threads?
A: Challenges in web scraping Threads can include handling dynamic content loaded by JavaScript, dealing with pagination, ensuring data integrity, and adapting to website changes.
Q: Can I share the scraped Threads data with others?
A: Sharing scraped data with others may have legal implications. Ensure you have the right to distribute the data and be mindful of any privacy concerns about the information collected.
Q: How can I ensure my web scraping code is efficient and robust?
A: Writing efficient and robust web scraping code involves error handling, rate-limiting, proper header settings, and regular monitoring for potential issues. Properly testing the code and adapting to website changes are also crucial for a successful scraping process.
Summary
In this tutorial of Threads web scraping, we explored how to extract Threads post data and user profile data using Python with Playwright. We leveraged background request capture, a suitable method for handling complex JavaScript applications like Meta\'s Threads.
We efficiently retrieved the required data without manual reverse engineering of GraphQL calls by employing background request capture. The Playwright library enabled us to control a headless browser, making the scraping process more accessible and practical.
To process the captured data, we harnessed the power of the jmespath JSON parsing library. Its versatility allowed us to reshape the dataset effortlessly, focusing on the most relevant information for our analysis and research.
As Threads is a new social network, we remain vigilant and committed to monitoring any changes in scraping techniques. We will continuously update this guide to ensure it remains relevant and reliable. Stay tuned for future updates and further enhancements to our Python Threads scraping services,
Don\'t hesitate to contact us for all your instant data scraping, mobile app scraping and web scraping service needs. We offer comprehensive and reliable solutions to help you extract valuable data from websites and mobile applications efficiently and effectively. Whether you require data for market research, sentiment analysis, brand awareness, or any other analysis, our team is here to assist you. Contact us today for high-quality, tailored scraping services to meet your requirements.
sources >> https://www.actowizsolutions.com/scrape-threads-data-using-python.php
tag : #ScrapeThreadsData
#ScrapeThreadsDataUsingPython
#ThreadsDataScraping
#ThreadsScraper