


Tag :
In academics, nothing seems helpful for researchers, students, and faculty members to obtain enough information for research than Google Scholar. Several features make this search engine handier and lifesaver, such as forward citations, academic literature, and auto-generated Bib TeX.
However, you can\'t perform that when you need a massive chunk of data from Google Scholar, owing to certain restrictions. In such a case, you can scrape Google Scholar data from the web search engine to collect the bulk of scholarly articles and academic resources.
If you are curious to know them, stay with this guide. It will help you gather knowledge of the steps of web scraping research papers from Google in a more convenient methodology.
What is Google Scholar?
Google Scholar is a free-to-read web search engine that provides complete text or meta of scholarly literature across various formats and topics ready for publishing. The index of Google Scholar includes online academic journals, books, theses, conference papers, dissertations, abstracts, technical reports, etc.
Is It Possible to Scrape Google Scholar?
Yes, it is effortless to scrape Google scholar data. Although, the process is a bit tricky. It is quickly possible if you have an authentic Google Scholar scraper to extract the literature without hassle.
You can quickly fetch bulk data, including research papers, academic resources, social networking sites, forward & backward citations database, and more.
List of Data Fields
The following data fields are available from the Google Scholar website
- Research papers
- Citations
- Author Profile
- Title
- Brief Description
- #Cited By
- # Versions
- Source Website
Scrape Google Scholar Data with Python and BeautifulSoup
Google Scholar is a vast resource for academic resources across the internet. Here, we will see Google Scholar data scraping steps using Python and BeautifulSoup. Using BeautifulSoup, we will extract information and fetch the data using Python Requests.
Let\'s understand the complete steps to scrape Google Scholar data using Python.
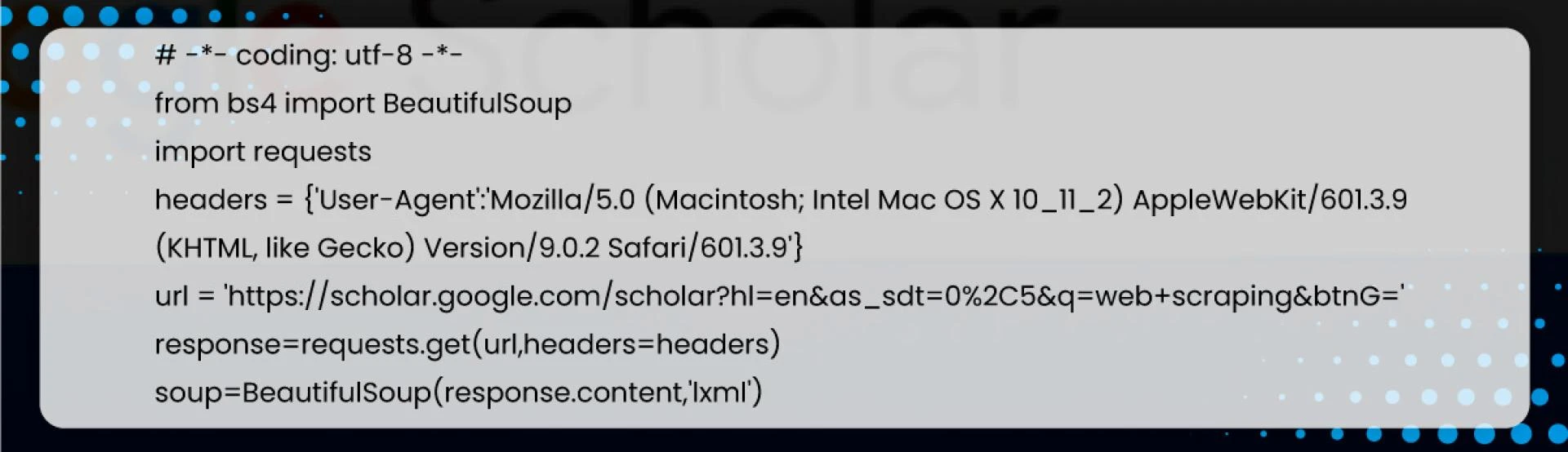
First, we will set up the BeautifulSoup and help use CSS selectors to query the page for meaningful data.
Now, let\'s analyze the Scholar search result for a desired destination. It appears like this:
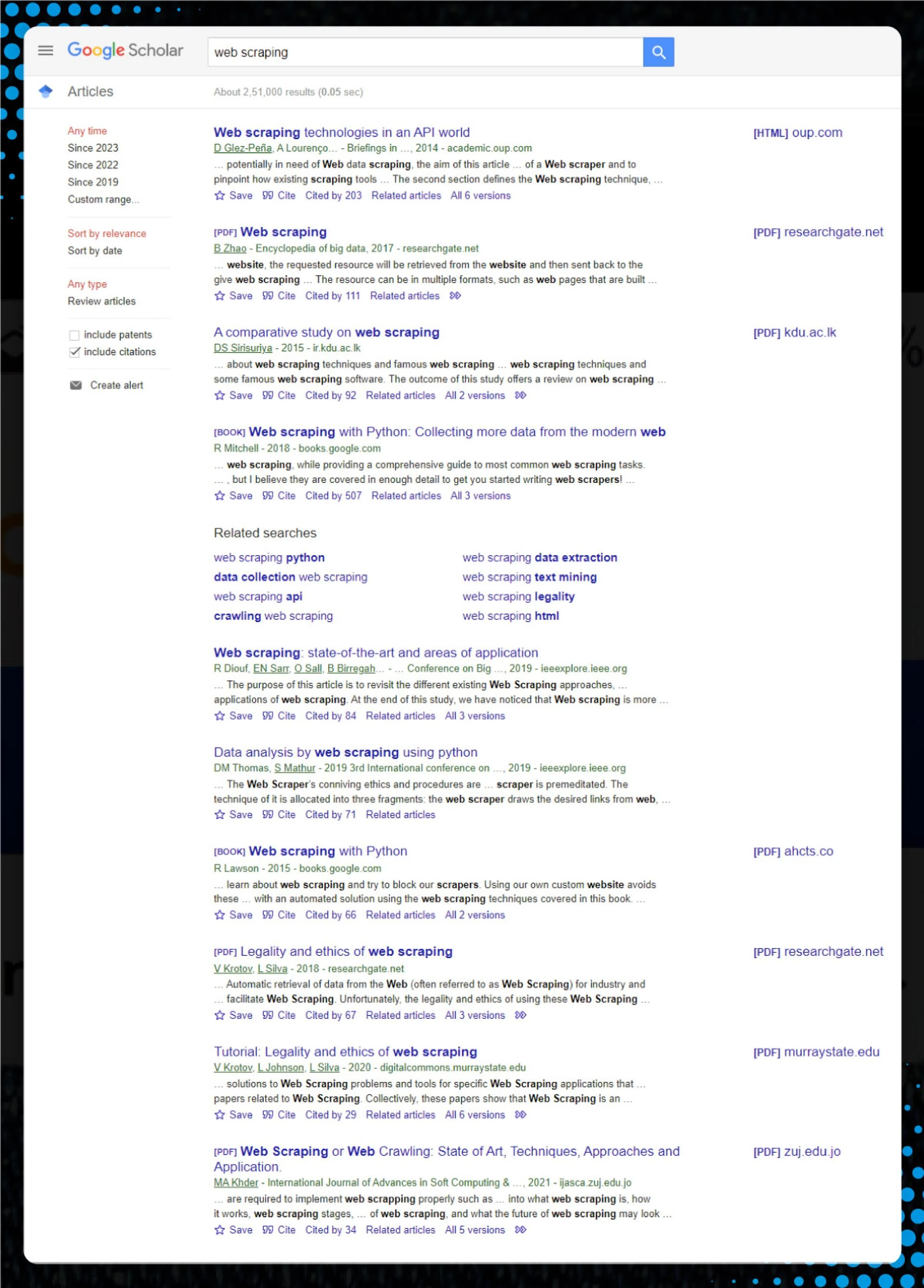
After inspecting the page, we assume that each item\'s HTML lies within a tag with the attribute data-lid with a null value.
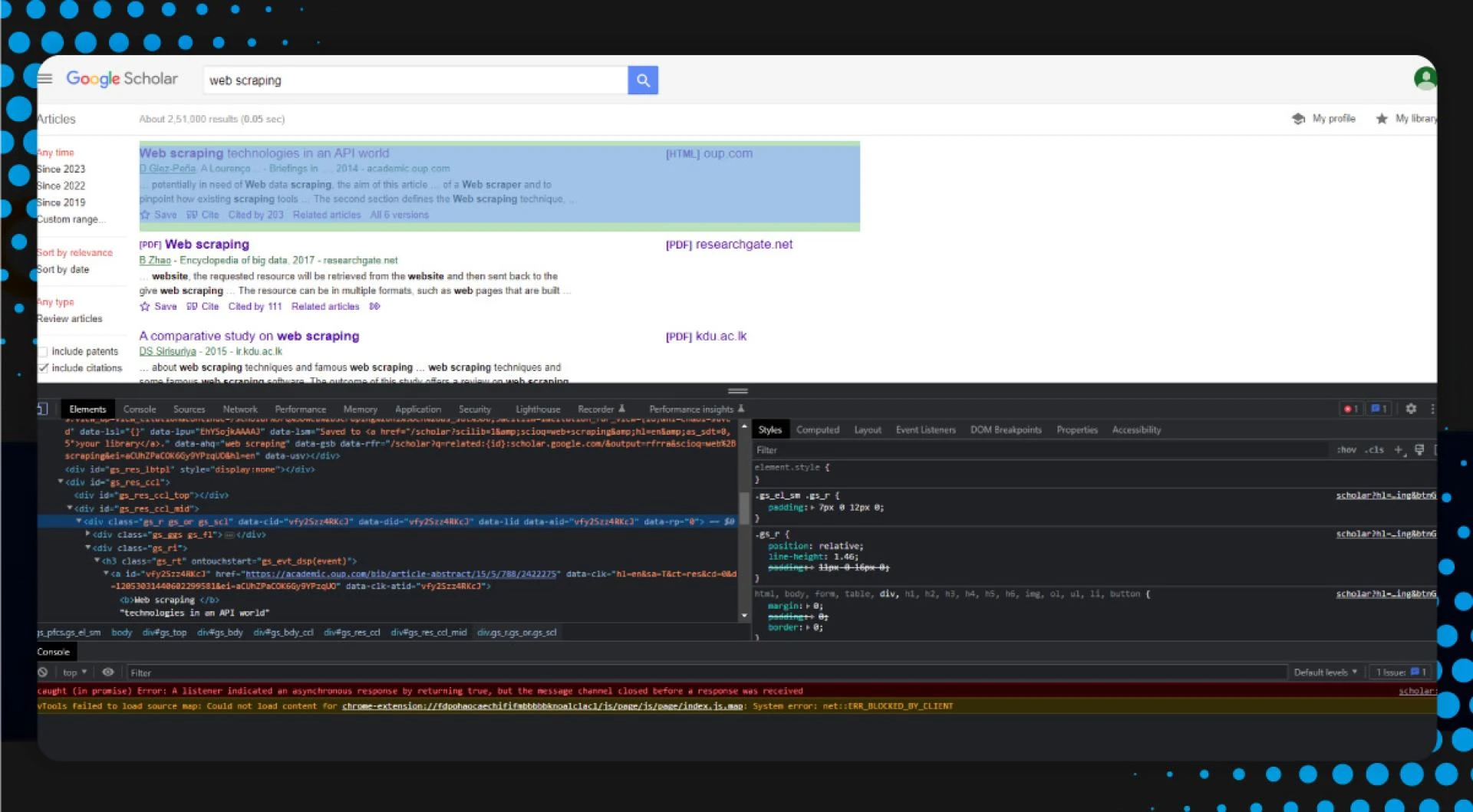
We will break the HTML document into data-lid elements having individual item information like this:

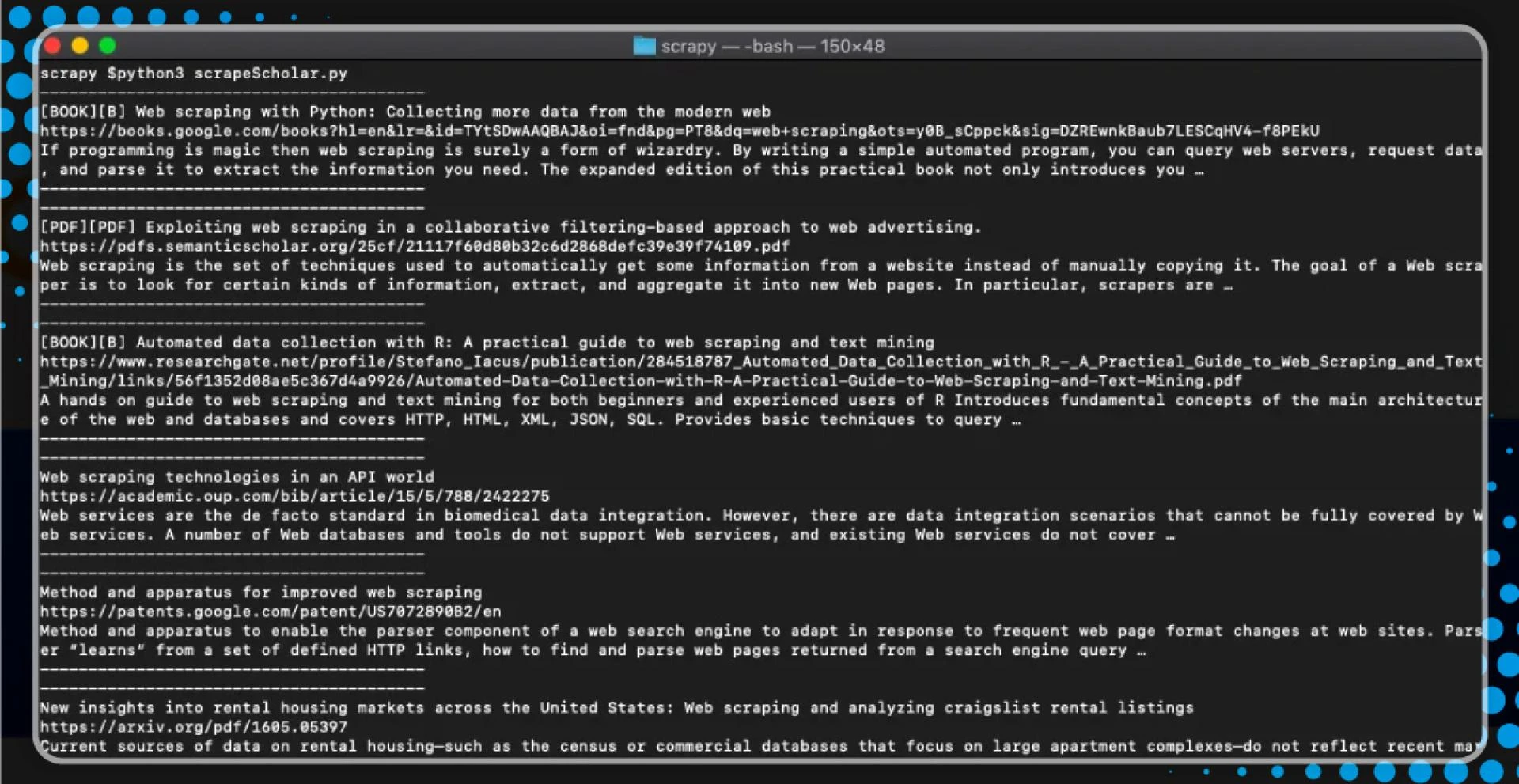
After running, we will find the following:
python3 scrapeScholar.pyThe code isolates the data-lid HTML
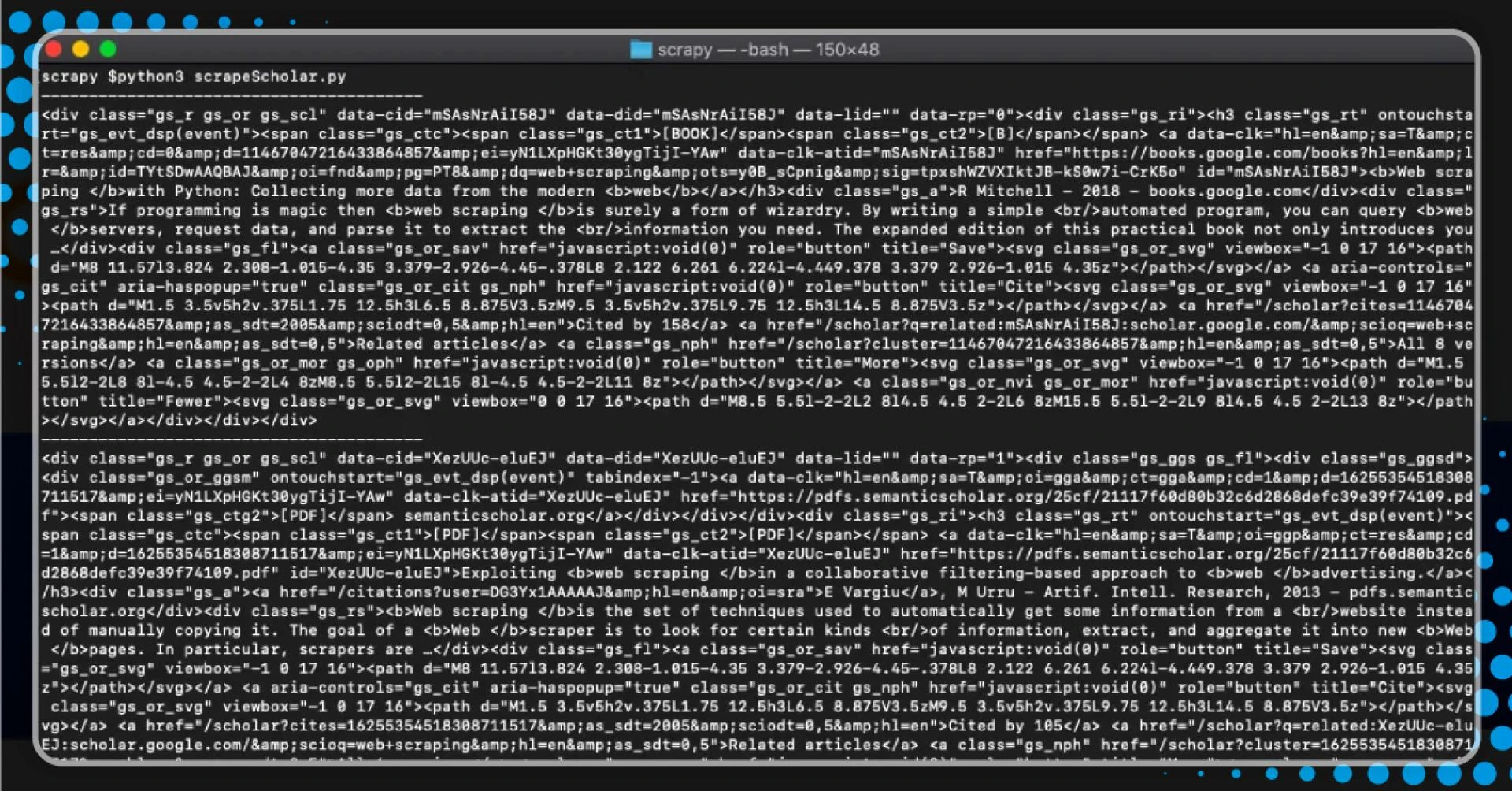
After further inspection, the titles in each search result are within a tag. Let\'s try to retrieve it.
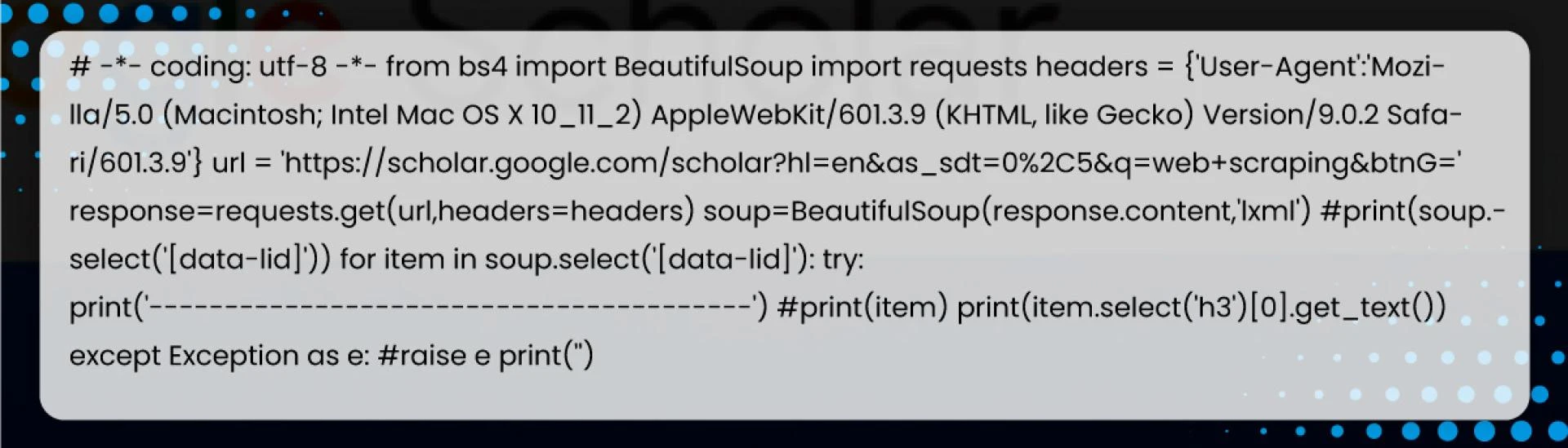
We will get the titles:
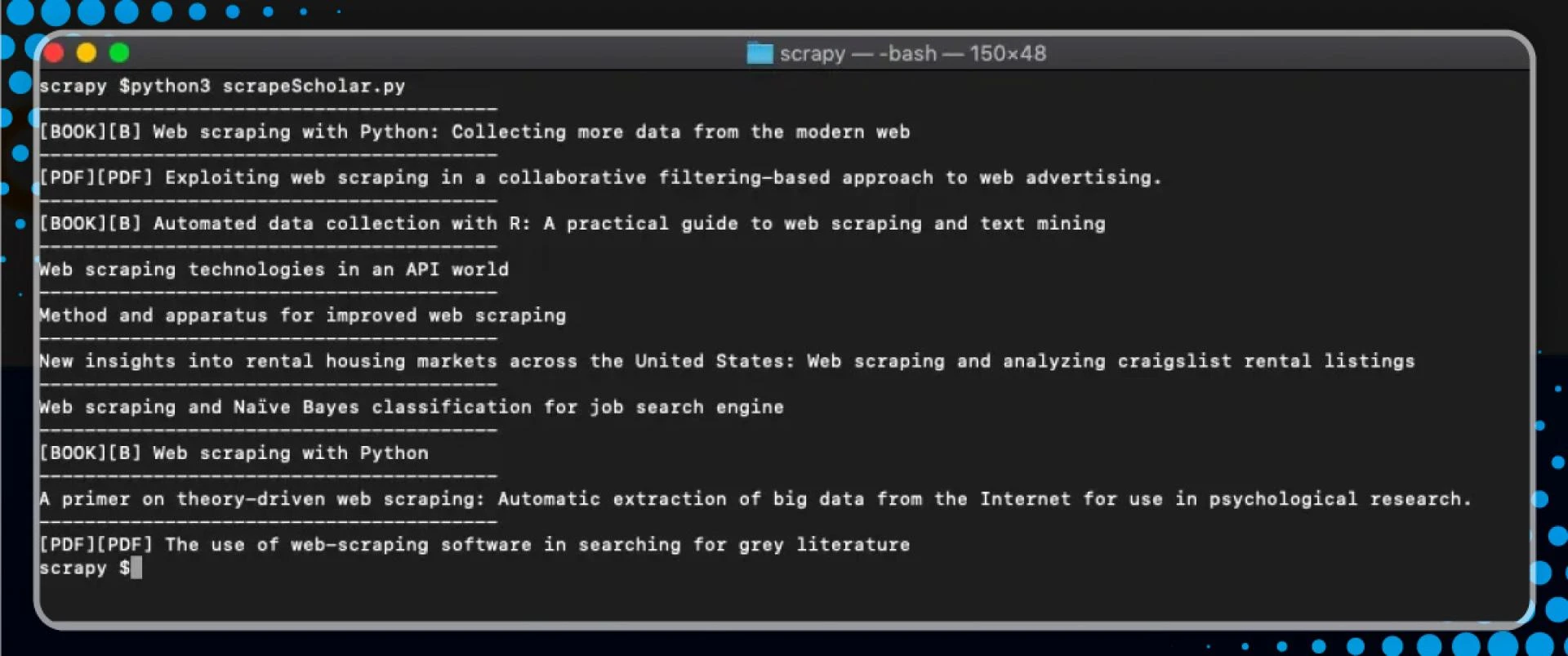
Now, let\'s get the other data pieces.
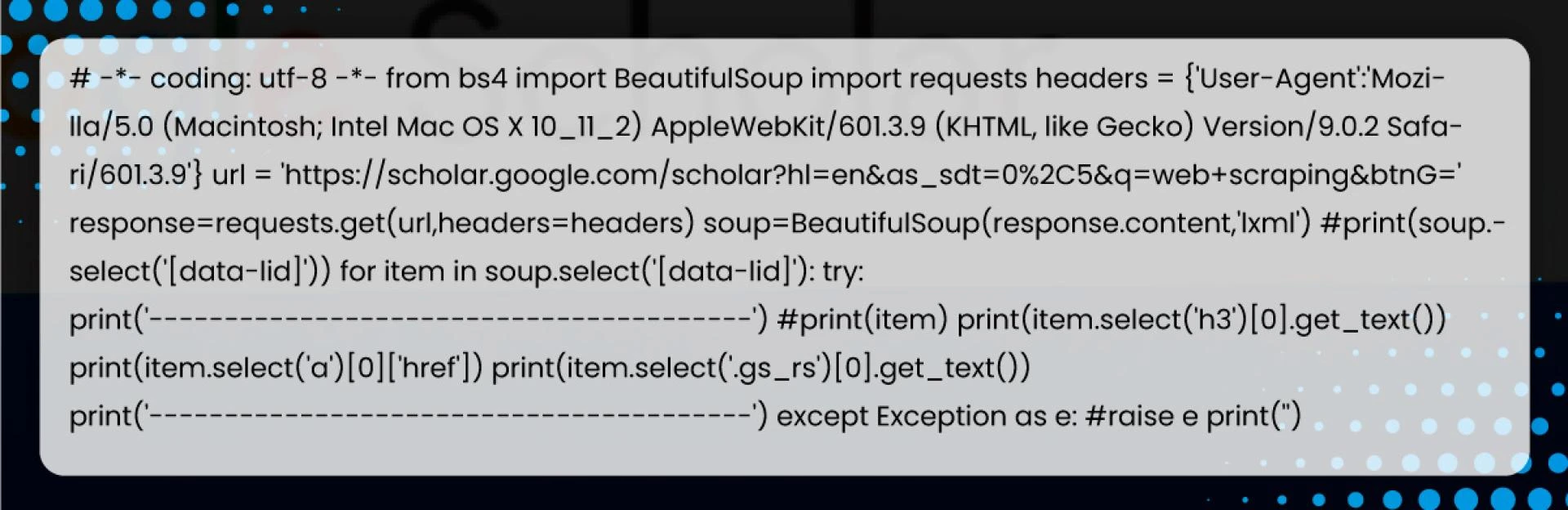
After running, we get
We have the link, summary, and title.
Scrape Google Scholar Organic Results Using Pagination
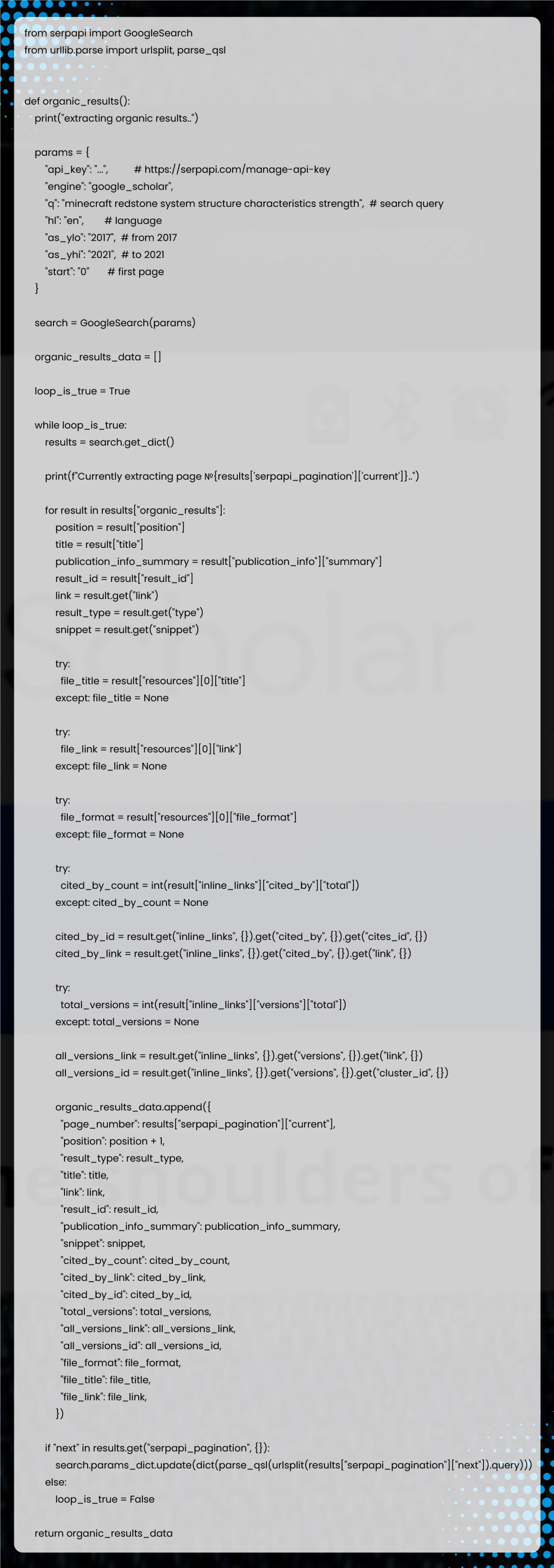
Explanations of Paginated Google Scholar Organic Results Extraction
Import serpapi and urllib libraries
1 from serpapi import GoogleSearch
2 from urllib.parse import urlsplit, parse_qslCreate and forward the search parameters to Google Search, where all extractions happen at the backend.

Generate a temporary list to store the data and later save it to a CSV file or pass it to the cite_results() function:
1 organic_results_data = []Extract all the data from available pages using a while loop.
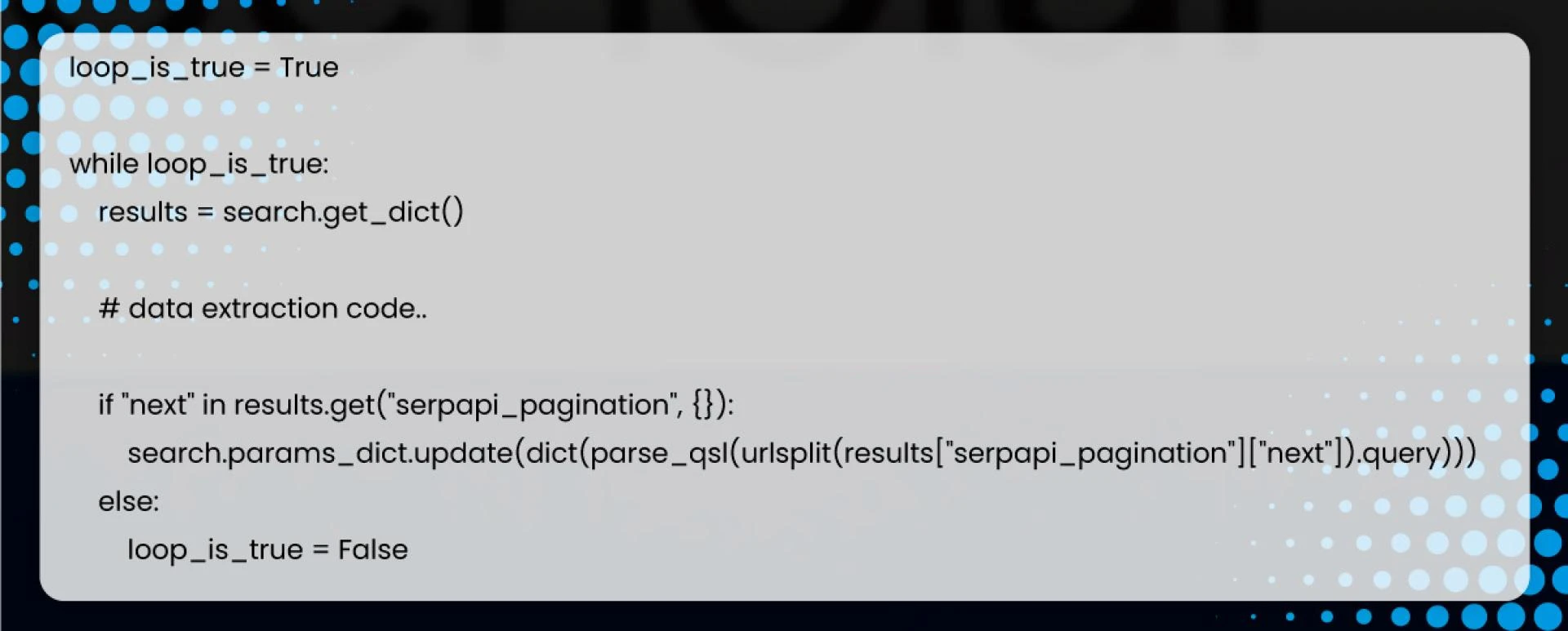
If no following page URL is available, it will break while looping by setting loop_is_true to False.
If there is a next page, search.params_dict.update will split and update the URL to GoogleSearch(params) for a new page.
Now, extract the data in a \'for\' loop.

Append the extracted data to a temporary list()
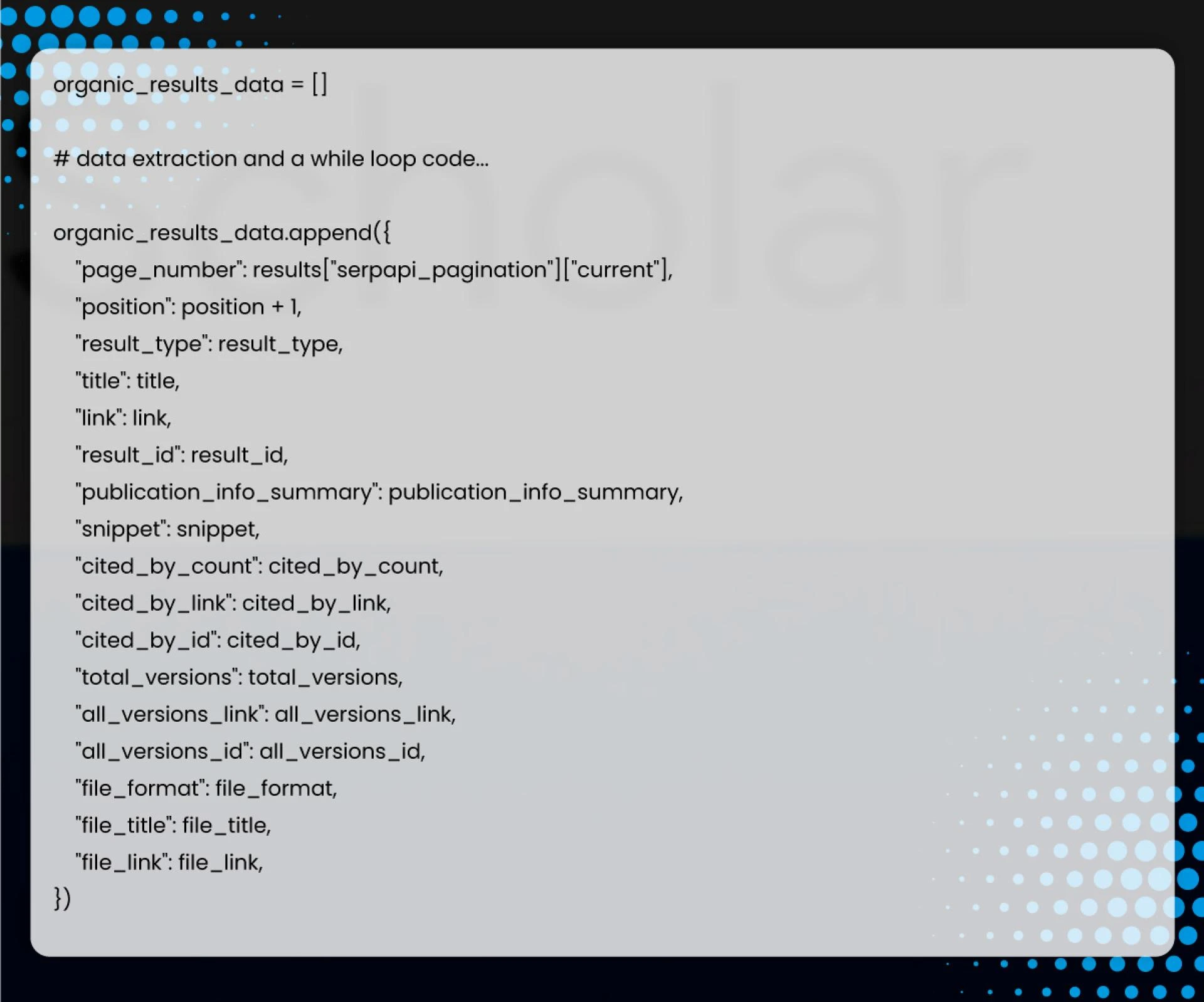
Run the quick list() data for use later in citation extraction.
1 return organic_results_dataScrape Google Scholar Cite Results Using Pagination
In this section, we will use the returned data from organic results and pass result_id to extract cited results.
Below is the cite extraction code snippet.

Explanation of Cite Results Extraction
Generate a temporary list() for storing citation data.
1 citation_results = []Set a \'for\' loop to repeat organic_results() and pass result_id to the \'q\' search query.

Again, set a next \'for\' loop.

Include the extracted data in a temporary list() as a dictionary.

Now, return the data to the temporary list()
Saving to CSV
In this case, we must pass the returned list of dictionaries from organic and cite results to the DataFrame data argument and save it to csv.

How to Save Results to CSV
Import organic_results() and cite_results() and panda library:

Save organic results to to_csv()
1 pd.DataFrame(data=organic_results())
2 .to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False)Save citation results to to_csv()
1 pd.DataFrame(data=cite_results())
2 .to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)Why Choose iWeb Data Scraping?
The internet possesses several web scraping service providers. But choosing the one that implements the proper techniques is a must. iWeb Data Scraping offers the best Google Scholar Data Scraping services with advanced techniques to produce accurate datasets. The structured data is in the desired format, including CSV, Excel, XML, etc. Moreover, web scraping Google Scholar search results will help aggregate information.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.
#Scrape Google Scholar
#google scholar crawler
#Scrape Google Scholar Data