



Web scraping is the initial project that people do after doing the Python basics. Usually, they begin with a static site like IMDB or Wikipedia. It is usually an easy task.
Extracting data from dynamic websites is a hard job to do. Let’s take an example. ULTA Beauty is America’s biggest beauty line store, and it is using technology to make the shopping for all beauty products a bit easier and more pleasurable. It is making an omnichannel approach to improve customer experience, whether they purchase online or in person. The concept of ULTA means "connected beauty." Our objective here is to help fragrance enthusiasts globally explore, find, and like the fascinating world of aroma.
In this blog, we’ll observe how to extract data from Ulta Beauty\'s Website. We will scrape the given data fields from individual Ulta Beauty pages. We\'ll utilize Python for scraping Women Fragrances Data from Ulta Beauty\'s Website and save that in the CSV file. After that, we will analyze data with Python.

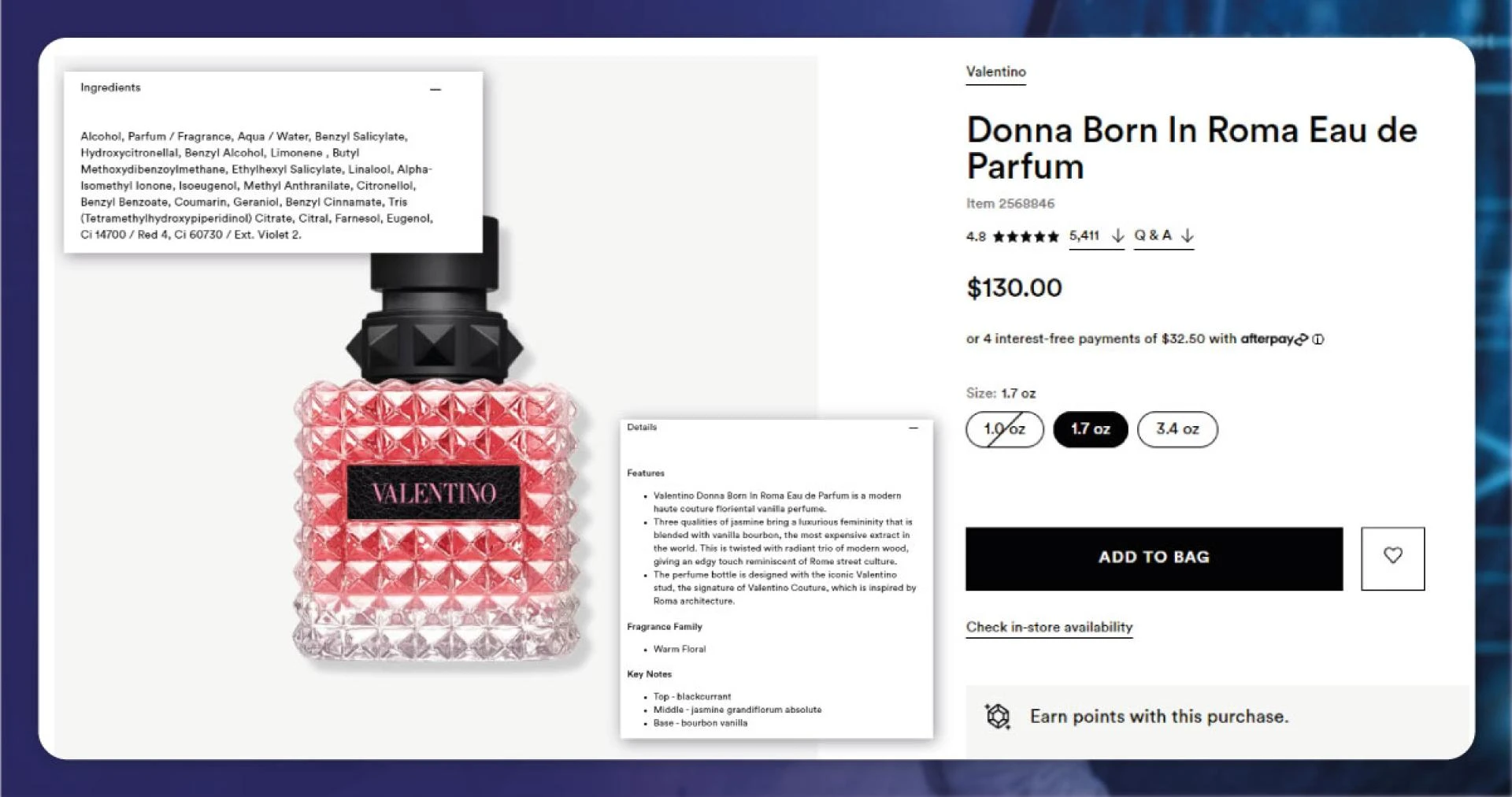
- Product Name
- Brand
- Details
- Fragrance Description
- Ingredients
- Number of Reviews
- Product URL
- Ratings
Web Scraping using Python Packages
In this blog, we will use Python for scraping data. Python has a vast and active community, meaning many frameworks and libraries can assist you using web scraping. For instance, BeautifulSoup is a modern library to parse XML and HTML documents.
Ulta Beauty is a dynamic website with dynamic content. Therefore, we have to utilize a headless browser to extract data. We have used a Selenium tool to extract data which you can use as a headless browser.
Importing Libraries:

The initial step is to import the necessary libraries. Here we utilize a blend of Selenium and BeautifulSoup to extract data. Therefore, we initially imported Selenium, Webdriver, BeautifulSoup, ElementTree (Etree), Unidecode, and Time modules.
We\'ve used BeautifulSoup with Etree libraries. BeautifulSoup parses HTML data into a machine-readable tree format for rapidly scraping DOM Elements. It permits scraping table elements and paragraphs with a particular Class, HTML ID, or XPATH.
Selenium is a specially designed tool for automating Web Browsers. Furthermore, it is beneficial to scrape data due to automation capabilities, including Clicking particular form buttons, Inputting data in the text fields, and scraping DOM elements to browse HTML codes.
These are essential packages to scrape data from the HTML pages.
We have installed Chrome & ChromeDriver with a Selenium package. A \'ChromeDriverManager library assists in managing a ChromeDriver executable utilized by a webdriver to control a Chrome browser.
To extract data, you have to understand where the data is positioned. For that, locating site elements is among the essential requirements of data extraction. There are some standard ways of finding a particular element on the page. For instance, you can search by tag names OR filters for a particular HTML class or ID or utilize XPath expressions or CSS selectors. However, as usual, the easiest way to locate an element is by opening Chrome dev tools and reviewing the elements you want.
Page Links Extraction
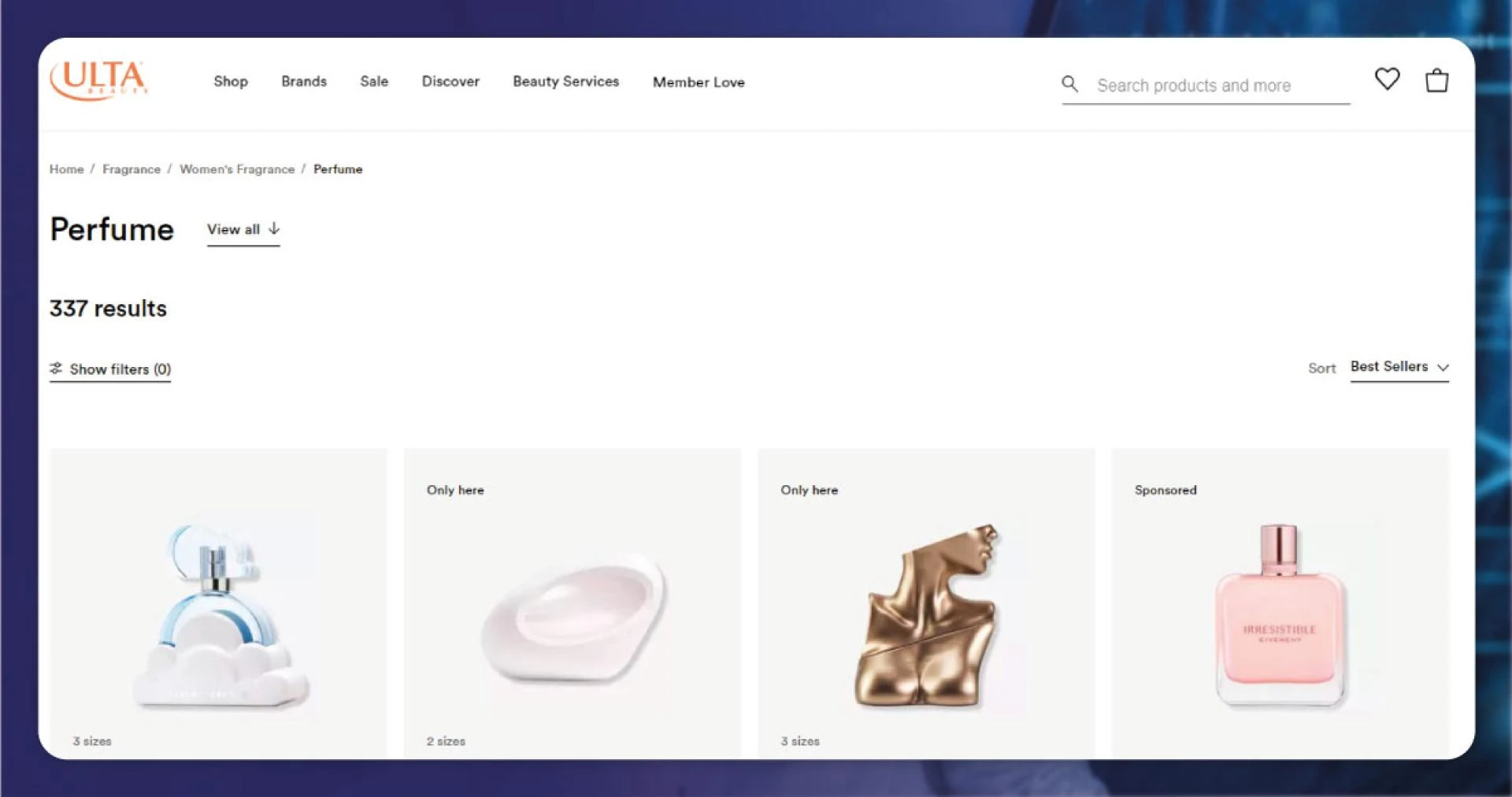
The second stage is scraping a resultant page link, looking for Women\'s Fragrances Products reclining on different web pages, and needing to visit one page to another to observe the enduring products.
So initially need to extract a site and gather URLs of various pages for search results. Here we have used a while loop to repeat through search results. The loop begins by navigating to present URLs using \'driver. Get ()\' technique. It obtains a page\'s HTML resource code through \'driver.page_source\' and parses that with a BeautifulSoup library. We have opened a website using Selenium and parsed a page\'s key content using BeautifulSoup.

Here, we have used the HTML class for finding elements. We require URLs for each page. After a while loop completes execution, we store all the page_url in a listing page_lst_link.
Product Links Extraction

The following step is scraping product links from resultant pages. With the scraped page links in a second step, we could easily scrape a resultant product link from consistent pages. Here, a ‘page_lst_link’ variable needs to list page links where you wish to extract product links. A code will repeat through every page link in a list and utilize a web driver for navigating that page. This will utilize BeautifulSoup for parsing the HTML of the page and scraping all the product links.
We require URLs for each Women\'s Fragrances product. Therefore, we make a for loop to get every product_url and save each product link in a list of product_links. Also, we have used the HTML class for locating the elements.
Making a Dataframe for Storing Data:

The following step is creating a dataframe for storing the scraped data. We have made a dataframe with nine columns, including Product Name, URL, Brand, Total Reviews, Fragrance Description, Ratings, Ingredients, and Details.
Information Scraping:

Here, we will recognize the required attributes from Website Ulta Beauty and scrape Product Names, Total Reviews, Brands, Ratings, Details, Fragrance Descriptions, and Ingredients for every product.
A function extract_content() technique extracts web page content at a specified URL with a Selenium library using a web driver. Then, the content is parsed with the BeautifulSoup library and reimbursed as an object called ‘lxml.html.HtmlElement’.

We passed the_url like an argument. Then, we stored requests from a URL in the page_content having a Selenium web driver. We made a product_soup variable by parsing the page_content using Beautifulsoup and making the dom with ElementTree. This technique returns a dom
that you can use for scraping particular elements from a page with methods like .cssselect() and .xpath().
Scraping a Product Brand:

Here is a function to scrape a brand name from the lxml.html.HtmlElement object with an XPath expression. Here, we iterate using a brand of every product list in sequence. Whenever a loop picks up a URL, we utilize Xpath to get the given attributes. When the attributes get scraped – the data will get added to a corresponding column. Data would sometimes be obtained using [“Brand”] the format. Therefore, we would remove those annoying characters here.
Product Name Scraping:

Here is a function to scrape a product name. The function looks similar to a Brand() function; however, it is proposed to scrape a product name from the lxml.html.HtmlElement object with the XPath expression. We repeat through a product name listing in sequence. Whenever a loop chooses a URL, we utilize Xpath to find the listed attributes here. Once you scrape the attributes, data will get added in the corresponding columns. Sometimes, data will get obtained with [“product name”] in the given format. Therefore, we would remove those undesirable characters here.
Correspondingly, we can scrape Total Ratings, Ingredients, and Ratings.
Total Product Ratings:

Product Ratings:

Product Ingredients:

In the following step, we call functions. Here, a loop iterates over rows of dataframe, scrapes the Product_url column for every row, and passes that to the extract_content() function to get page content like an
lxml.html.HtmlElement object. Then, it calls many functions (Reviews(), Brand(), Product(), Ingredients(), and Star_rating()) on a product_content object for scraping detailed data from pages.
Product Price Scraping:

Here is a function to scrape a product price from web pages. We repeat the pricing of every product listing in sequence. Occasionally when we try scraping data using BeautifulSoup Python, it can\'t use dynamic content as it is an HTTP user and won’t be able to use it. In this case, we would utilize Selenium for parsing data; Selenium works as Selenium is a complete browser with the JavaScript engine. If a loop chooses a URL, we utilize Xpath to get the given attributes. When you scrape the attributes, data will be added to a corresponding column. Data would sometimes get obtained in different formats to remove unwanted characters.
Likewise, we can scrape the Fragrances Description and Information.
Fragrance Product Description:

Product Details:

def Detail():
We must click the ‘+’ button to scrape the given details. Then we would click on a button through Selenium and Xpath.

The ‘Details’ includes data about the Composition, Scent Type, Fragrance Family, Key Notes, and Characteristics of every Women\'s Fragrance product. Therefore, we can scrape that data to another column if needed.
After that, we call functions. Here a loop that iterates over rows of the dataframe and scrapes detailed data from web pages at URL in a Product_url column of every row. You can scrape data using Price(), Detail(), and Fragrance_Description()functions, and it is added to the corresponding columns of a dataframe.
We will write data on every woman\'s Fragrances into a csv file.

Conclusion
Want to get a competitive benefit by collecting product data using web scraping?
Reveal the power of data using our data scraping services. Don\'t allow your competitors to stay ahead! Contact Actowiz Solutions today to see how we will help you get a competitive edge!
know more : https://www.actowizsolutions.com/extract-dynamic-websites-data-with-the-help-of-python.php