



The e-commerce business has become more data-driven. Extracting Amazon product data and other significant e-commerce sites is vital to competitive intelligence. You can get a massive amount of data on Amazon alone. Scraping this data daily is an enormous task.
At Actowiz Solutions, we deal with many customers to help them access the data.
Assumptions
Some assumptions are there that will provide you with a rough idea about the scale, challenges, and efforts we would be working with:
- Four websites are there with anti-extraction technologies implemented.
- The data volume differs from 3 to 7 million per day, according to the day of the week.
- The refresh rate is different for various subcategories. Out of 20 subcategories, 10 require refresh every day; five require data once every two days, 3 require data once every three days and two require data once a week.
- You require data from 20 to 25 subcategories with the electronics category from the website. The total categories & subcategories are about 450.
- You want to scrape product data from 20 big e-commerce sites, including Amazon.
Understand E-Commerce Data
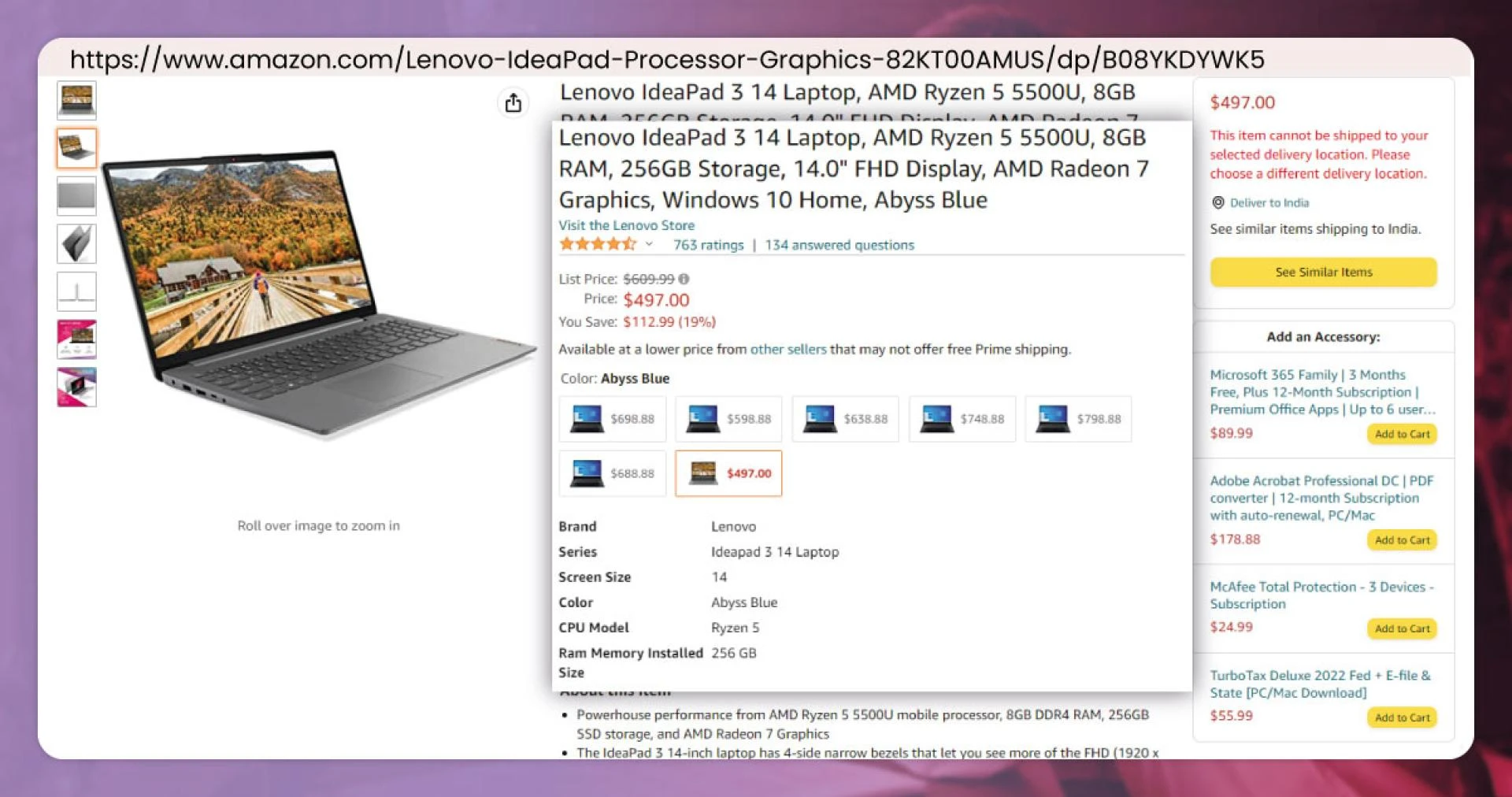
We have to understand the data that we’re scraping. For the demonstration objective – let’s select Amazon. Note the different fields that we want to scrape:
- Product’s Name
- Product’s URL
- Product’s Description
- Average Star Ratings
- Breadcrumb
- Discounts
- Image URL
- Pricing
- Stock Information
The Frequency Rate
The refresh frequency rate is different for various subcategories. Of 20 subcategories, 10 require refresh every day; five require data once every two days, 3 require data once every three days, and two require data once a week. The frequency might change later, as per how the priorities of business teams change.
Understanding Particular Requirements
When we work on large-scale data scraping projects using enterprise customers - they have special needs. You can do it to ensure internal compliance guidelines or better efficiency of the internal procedure.
Let’s go through some general, special requests:
Get a copy of scraped HTML ( unparsed data) deserted into the storage system, including Amazon S3 or Dropbox.
Make an integration using a tool for monitoring the development of data scraping. Integrations might be an easy slack integration to inform when data delivery gets completed or build a composite pipeline for BI tools.
We have screenshots from product pages.
In case of such requirements - you have to plan forward. A general case is saving data to analyze it later.
Reviews
In a few cases, you have to scrape reviews, also. A general case is improving brand reputation and brand equity through analyzing reviews. Review scraping is a particular case; most teams miss it during project planning, exceeding the budget.
The unique things about reviews include the following –
There could be 10000 reviews for one product like iPhone 10. If you wish to scrape 10000 reviews – you’ll have to send 10000 requests. While you estimate the resources – it is required to get considered.
Data Scraping Challenges
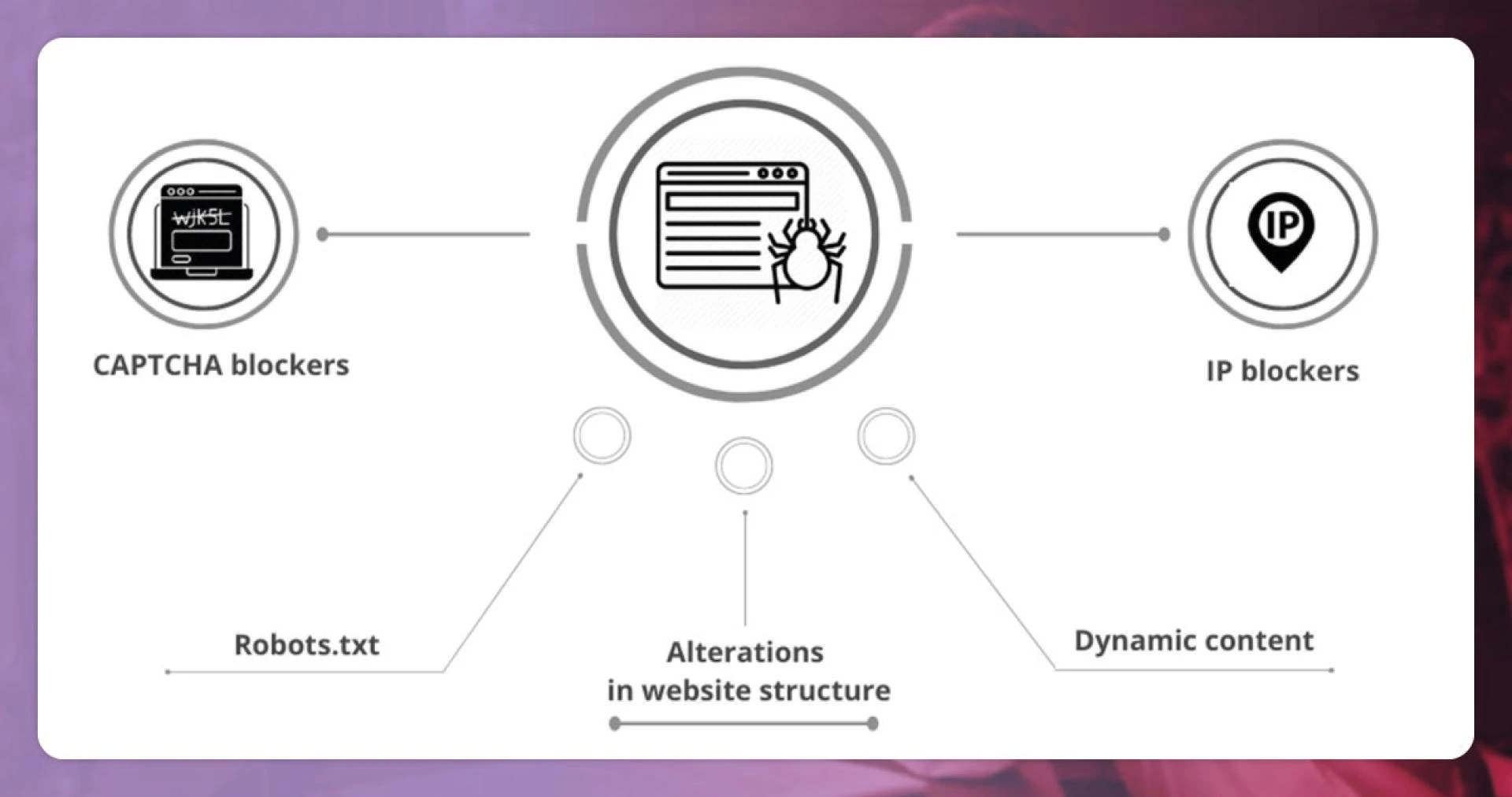
1. Maintaining & Writing Scrapers
You can utilize Python for writing scrapers to scrape data from e- commerce sites. Here, we have to scrape data from 20 subcategories from a site. As per structural variations, you require multiple parsers in your scraper for getting data.
Amazon, with other more significant e-commerce sites, frequently changes patterns of categories & subcategories. Therefore, a person accountable for maintaining data scrapers must continuously adjust a scraper code.
At Actowiz Solutions, we make an early warning system for site changes with Python.
2. Big Data & Data Scraper Management System
Dealing with too many scrapers via terminal isn’t an excellent idea. You have to get productive ways of handling them. At Actowiz Solutions, we create a GUI that can be utilized as an interface for underlying a platform to deploy and manage scrapers without relying on a terminal each time.
Managing enormous data volumes is a challenge; you either have to create an in-house data warehousing infrastructure or utilize cloud- based tools like Snowflake.
3. Auto Data Scraper Generator
Once you create many scrapers, the next step is improving your data scraping framework. It would help to think about creating an auto data scraper framework when you get substantial scrapers. You can get common structure patterns and utilize them to make scrapers quickly.
4. Anti-Scraping with Change in Anti-Scraping
Websites will use anti-scraping technologies to make it difficult to scrape data. They either provide their IP-based blocking solutions or install third-party services. Providing anti-scraping on a big scale is not easy. You have to buy many IPs and resourcefully rotate them.
Challenges to Data Quality

A business team that consumes data is concerned about data quality. Insufficient data can make their work difficult. The data scraping team often neglect data quality till a big problem occurs. You require tight protocols for data quality at the start of a project if you’re utilizing this data on any live product or for customers.
Contact Actowiz Solutions if you work on a POC which needs web data as the main component.
The records that don’t meet quality guidelines would affect the general data integrity. Ensuring that data meets all the quality guidelines while crawling is problematic because it requires it to get performed in real- time. Broken data may result in severe problems if you use it to make business decisions.
Let’s go through the common errors in extracted product data from e- commerce sites:
1. Duplicates
While collecting and combining data, it’s pretty possible that duplicates come as per the scraper’s logic and also how well Amazon play. You have to discover them and remove them. It proves to be a headache for all data analysts.
2. Data Validation Errors
A field you are extracting needs to be an integer; however, when extracted, it turned out to be the text. This type of error is named a data validation error. You have to create rule-based test frameworks for finding and flagging this error. At Actowiz Solutions, we describe all data items\' data kinds and other properties. All data validation tools would flag to a project QA team in case of any inconsistencies. All the flagged items would be manually verified and reused.
3. Coverage Errors
If you are extracting millions of products –you might miss numerous items because of request failures or inappropriate design of a scraper logic. You can call it item coverage variation.
At times, the data scraped may not have all the necessary fields. That is what we know as field coverage variation. A test framework needs to recognize two kinds of errors.
Coverage variation is a crucial problem for self-servicing tools and Data as a Service empowered by self-servicing tools.
4. Product Errors
Data depiction and unavailability in different ways cause data confusion. Cases are where different variants of similar products are required to get extracted. In these cases – there could be data discrepancy across diverse variants.
- E.g., mobile phones could have variations in RAM size, price, color, etc.
- E.g., Representing data in SI system and metric system. Currency variations.
- Your Q&A team framework requires dealing with these challenges also.
5. Changes in Site
Amazon and other big-size e-commerce sites change their designs frequently. It can be site-wide changes or in some categories. Scrapers typically need adjustments in a few weeks, like minor changes in a structure might affect fields you extract or provide you with insufficient data.
If you create an in-house team, you require a pattern change finder to detect changes and stop scraper. When you make adjustments – you could resume extracting amazon – saving significant money and computer resources.
Challenges of Data Management
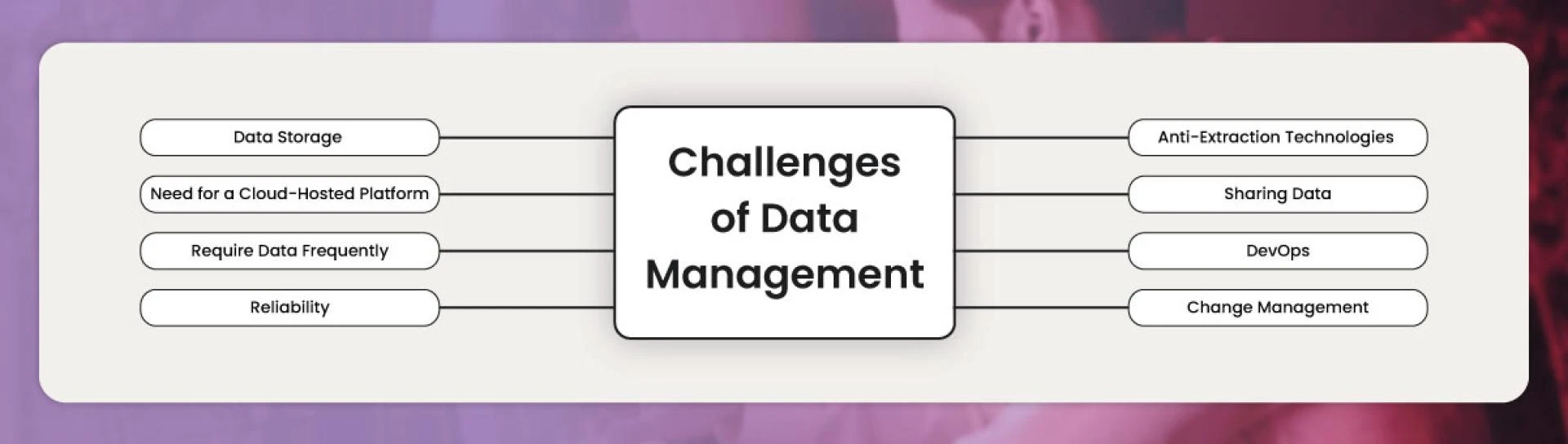
Managing big-volume data comes with many challenges. The data amount you collect will continue to upsurge. Might be you get data, storage, and use of data comes with a completely new level of functional and technical challenges. However, organizations won’t get the finest value of it without a suitable foundation to use more significant data amount.
1. Data Storage
You have to store data in a database to do the processing. Your tools for Q&A and other systems would get data from a database. Your database should be fault-tolerant and scalable. You also want a backup system for data access if the primary storage fails somehow. There were reported cases of ransomware used to hold data hostage. You require a backup for all records to deal with the abovementioned cases.
2. Need for a Cloud-Hosted Platform
You also need a data scraping platform if you need data for your business. You just can’t run data scrapers to a terminal each time.
3. Require Data Frequently
If you want data frequently and program the scheduling section – you want a platform having an integrated scheduler for running a scraper. A visual user interface is better, as even non-technical people can use the data scraper with only one click.
4. Reliability
Running web scrapers on local machines is not a great idea. You require a cloud-hosted platform to do a reliable data supply. Use data scraping services of Amazon Services or Google Cloud platform for building a cloud-hosted platform.
5. Anti-Extraction Technologies
You require the ability to integrate tools to avoid anti-extraction technologies, and the finest way to do it is by connecting their API with your cloud-based platform.
6. Sharing Data
Sharing data with internal stakeholders could be automated if you combine data storage with Azure, Amazon S3, or similar services. The majority of analytics and other tools for data preparation available in the market get native Google Cloud or Amazon S3 platform integrations.
7. DevOps
In DevOps, any application begins, which can be chaotic. But not anymore! Google Cloud, AWS, and similar services offer flexible tools to assist you in the making applications more reliably and rapidly. These services streamline DevOps, manage data platforms, deploy applications, extract code, and monitor your applications and infrastructure performances. So the best option is to select a cloud platform and utilize their services as per preferences.
8. Change Management
There will be changes as your business team utilizes scraped data. These changes might be in the data structure, changes in refresh frequencies, or something else. Organizing the changes is process-driven. Depending on our experiences – the finest way of managing changes is to do fundamental things right.
Using one contact - There could be twenty people in the team, but there should be only one person to whom you should contact for any change requests. This person will assign the tasks and make them done.
Use of a ticketing tool – The best way to deal with change management is by using an internal ticketing tool. If any changes id needed, you need to open a ticket, work with the stakeholders and complete it.
Conclusion
It is crucial to categorize the Business team and data team. If team members are involved in both these, the project will fail. Let the data team do their work, and a similar applies to the Business team.
For more details or a free consultation, contact Actowiz Solutions today! You can also reach us for all your mobile app scraping and web scraping services requirements.
know more : https://www.actowizsolutions.com/extract-big-size-e-commerce-websites-like-amazon-at-a-bigger-scale.php