How to Scrape Restaurant Data from Zomato

In the digital age, data is a valuable asset, especially when it comes to businesses such as restaurants and pubs. However, understanding the significance of data for marketing, research, and analysis, many companies are eager to build comprehensive databases that encompass essential details about various establishments. One popular source for this information is Zomato, a prominent online platform that provides users with many information about restaurants, pubs, and other eateries. In this article, we will explore how to scrape restaurant data from Zomato to create a database of these establishments in India’s eight major metro cities.
About Web Scraping
Web scraping is an automated process of gathering data from websites. It entails developing code that systematically navigates through web pages, locates pertinent information, and organizes it into a structured format, such as a CSV or Excel file. Nevertheless, it is of utmost importance to acquaint ourselves with the terms of service of the target website before commencing web scraping. This precautionary step ensures that the web scraping restaurants data procedure adheres to all rules and policies, preventing potential violations.
About Zomato
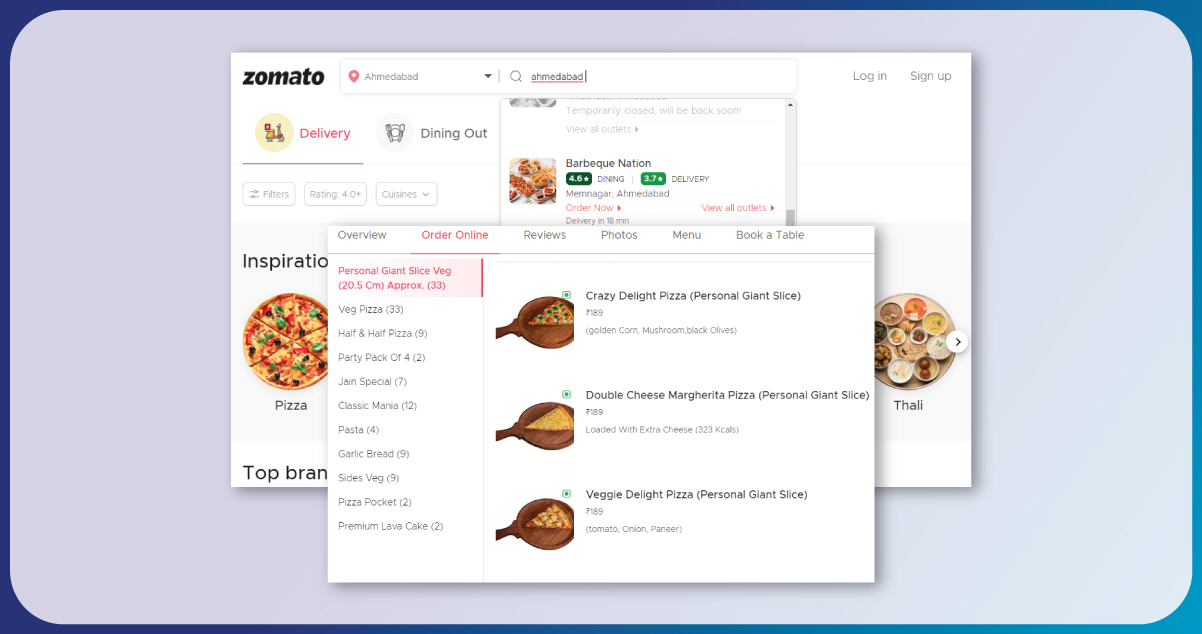
Zomato is a leading online platform that provides a comprehensive guide for users seeking information about restaurants, cafes, bars, and other eateries. It offers a wide range of details that can assist users in making informed decisions when dining out or ordering food. The platform goes beyond merely providing basic restaurant listings and delves into more intricate aspects that enrich the dining experience. One of the primary features of Zomato is its extensive database of restaurants, which spans various cities and countries. Users can access this information to explore their diverse culinary options. Each restaurant listing typically includes essential data, such as the establishment’s name, location, cuisine type, and opening hours. Scrape Zomato food delivery data to gain insights into customer ordering behavior.
List of Data Fields
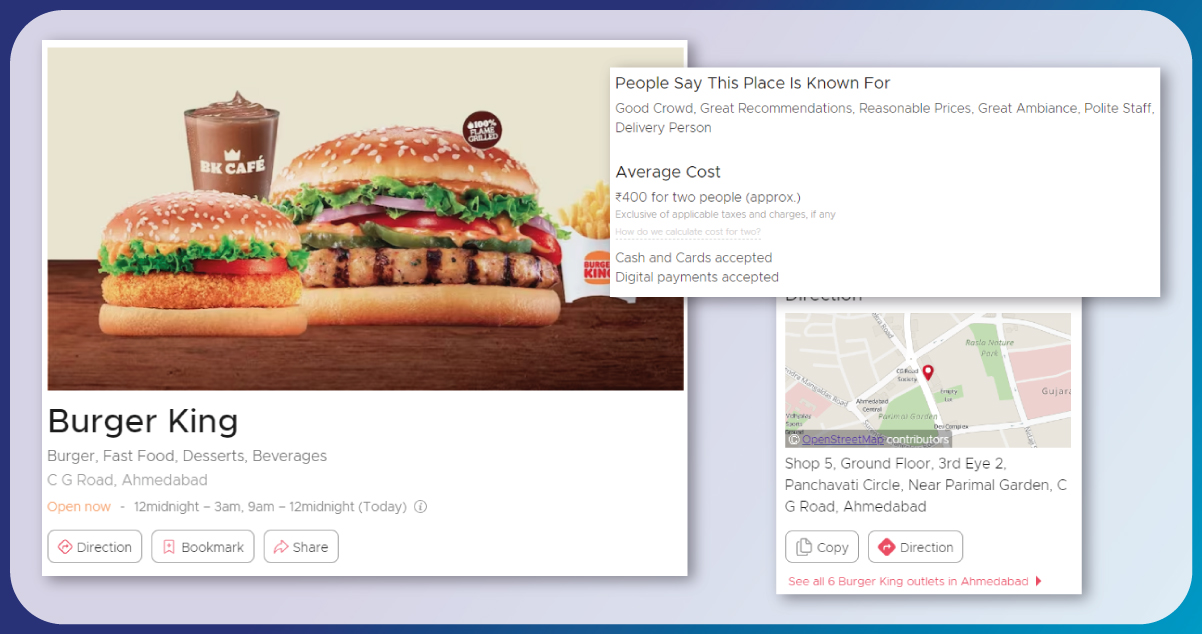
- Restaurant Name
- Address
- City
- State
- Pin Code
- Phone Numbers
Web Scraping Using Python and BeautifulSoup
We have chosen Python, a highly versatile and popular programming language, for our web scraping restaurant data from Zomato project. To extract the required data from Zomato’s web pages, we will leverage the power of the “Beautiful Soup” library. This Python library is specifically designed to parse HTML content efficiently, enabling us to extract relevant information seamlessly. With the combined strength of Python and Beautiful Soup, we can efficiently and precisely automate gathering the necessary data from Zomato’s website.
Step-by-Step Guide to Scraping Restaurant Data from Zomato
1. Import Necessary Libraries:
When you Scrape Restaurants & Bars Data, make sure you have the required Python libraries installed. Install “requests” and “Beautiful Soup” libraries if not already in your Python environment.
2. Identify Target URLs:
Determine the URLs of Zomato’s web pages containing the restaurant data for each of India’s eight major metro cities. These URLs will serve as the starting points for our web scraping.
3. Send HTTP Requests:
Use the “requests” library to send HTTP requests to each identified URL. It will fetch the HTML content of the web pages, allowing us to extract relevant data.
4. Parse HTML Content:
Utilize “Beautiful Soup” to parse the HTML content retrieved from the web pages. The library will help us navigate the HTML structure and locate specific elements that contain the desired information, such as restaurant names, addresses, contact details, etc.
5. Extract Data and Store:
Once we have successfully located the relevant elements in the HTML, extract the required data seeking help from Food Delivery And Menu Data Scraping Services. Gather details such as restaurant names, addresses, city, state, PIN codes, phone numbers, and email addresses. Store this information in a structured format, such as a CSV file, database.
6. Data Cleaning and Validation:
After extracting the data, performing data cleaning and validation is crucial. This step involves checking for duplicate entries, handling missing or erroneous data, and ensuring data consistency. Cleaning and validating the data will result in a more accurate and reliable database.
7. Ensure Ethical Web Scraping:
It is essential to adhere to ethical practices throughout the web scraping process. Respect the terms of service of Zomato and any other website you scrape. Avoid overloading the servers with excessive requests, as this could cause disruptions to the website’s regular operation.
8. Update the Database Regularly:
To keep the database current and relevant, consider setting up periodic updates. Restaurant information, such as contact details and operating hours, can change over time. Regularly scraping and updating the database will ensure users can access the most up-to-date information.
Important Considerations:
Respect Robots.txt: Before scraping any website, including Zomato, check the “robots.txt” file hosted on the site to see if it allows web scraping and if there are any specific rules or restrictions you need to follow.
Rate Limiting: Implement rate limiting to avoid overloading the Zomato server with too many requests in a short period.
Update Frequency: Regularly update your database to ensure the information remains relevant and up-to-date.
Conclusion: Building a database of restaurants and pubs in India’s major metro cities from Zomato using Zomato scraper is an exciting project that requires web scraping skills and a good understanding of data management. By following ethical practices and respecting website policies, you can create a valuable resource that is helpful for marketing research, analytics, and business growth in the hospitality sector. Remember to keep the data accurate and updated to maximize its utility. Happy scraping!
know more:https://www.iwebdatascraping.com/scrape-restaurant-data-from-zomato.php