How To Scrape Data From Flipkart Website Using Python?
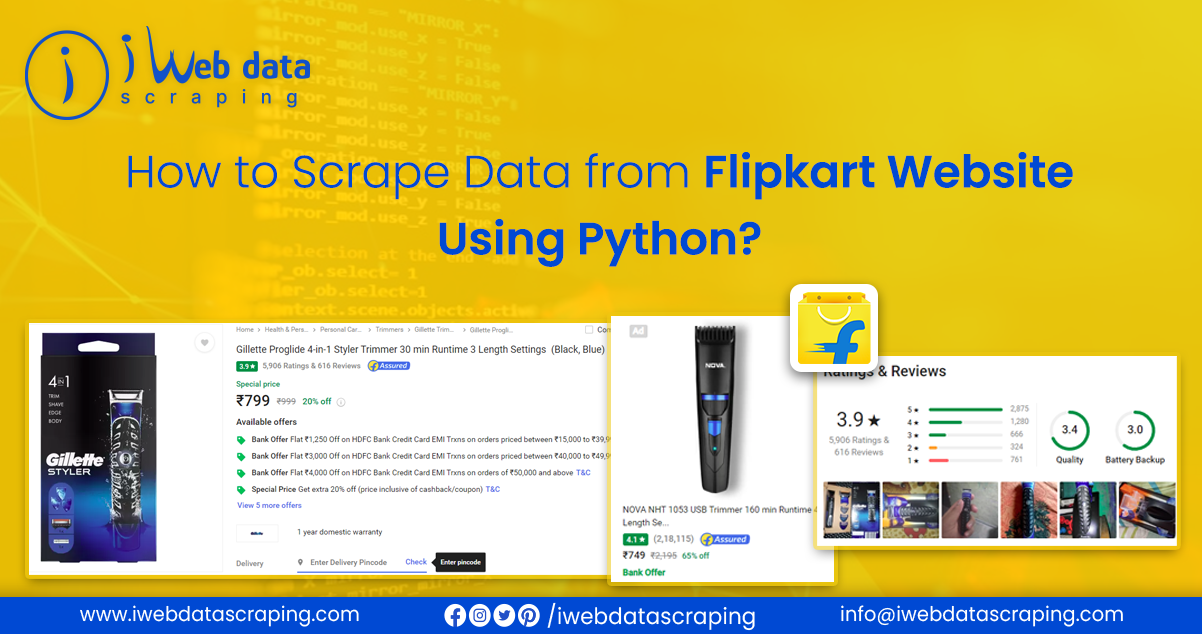
Web scraping is the ideal solution to retrieve a large amount of data from multiple websites efficiently. It automates the process, eliminating the need for manual data collection from each website.
Examining a webpage’s structure and HTML content allows you to identify the specific elements and data you want to extract. These elements include text, tables, images, links, and more. Using Python’s web scraping libraries, you can write scripts to automate the process of retrieving data from websites. The libraries provide functions and methods to fetch web page content, parse the HTML, and extract the desired data. This article briefly explained how to scrape Flipkart product data using the most common scraping methods.
Data scraping from an Ecommerce website with Python enables you to collect information for various purposes, such as market research, data analysis, price comparison, sentiment analysis, and more. However, it is essential to note that when performing web scraping, you should be mindful of the website’s terms of service and legal implications.
In this Python-focused article, we will explore the concept of web scraping and demonstrate how to extract data from a website. Before that, we will emphasize what web scraping is and its application.
About Flipkart: Flipkart is one of the largest e-commerce platforms in India. It was founded in 2007 by Sachin Bansal and Binny Bansal and started as an online bookstore. Over the years, it has expanded its product range and services to become a comprehensive online marketplace.
About Web Scraping Flipkart Data & Its Application
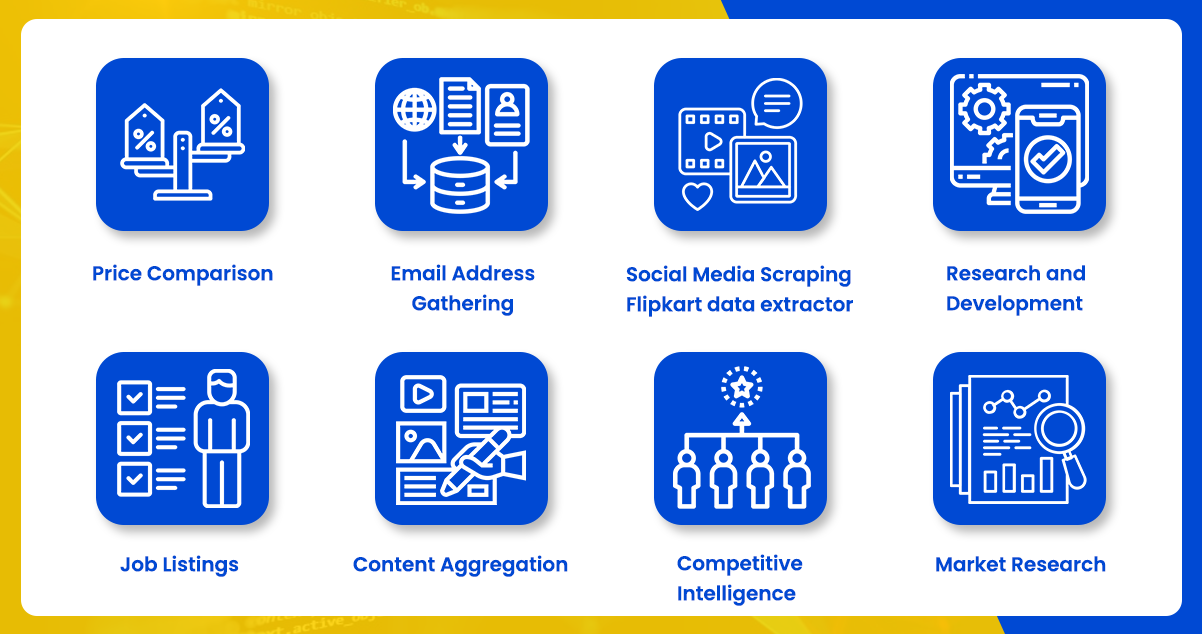
Web scraping is an automated technique that extracts essential data from websites. The data found on websites is typically unstructured, but web scraping enables the collection and organization of this unstructured data into a structured format. Various approaches to performing web scraping include utilizing online services, APIs, or writing custom code. Scrape Flipkart data to gather large amounts of data from websites for various purposes. Let’s explore some typical applications of web scraping:
- Price Comparison: Web scraping tools can collect data from multiple online shopping websites to compare the prices of products. The price monitoring service helps consumers find the best deals and make informed purchasing decisions.
- Email Address Gathering: Companies engaged in email marketing often use web scraping to collect email addresses from websites. This data is helpful for targeted marketing campaigns or building mailing lists.
- Social Media Scraping: Flipkart data extractor helps extract data from social media platforms like Twitter, enabling businesses to monitor trends, gather user opinions, and perform sentiment analysis for market research.
- Research and Development: Collecting data using Flipkart data extraction services allows the collection of large datasets, including statistics, general information, etc. This information is helpful for research purposes, surveys, or to gain insights for development projects.
- Job Listings: Web scraping tools can aggregate job listings from various websites, consolidating them in one place for easy access. It helps job seekers find relevant opportunities more efficiently.
- Content Aggregation: Web scraping gathers news articles, blog posts, and other content from multiple sources. This aggregated content helps create curated news feeds, build content libraries, or provide information for research purposes.
- Competitive Intelligence: Companies can utilize web scraping to monitor their competitors’ websites and track pricing changes, product updates, or marketing strategies. This data can inform business decisions and help stay competitive in the market.
- Market Research: Web scraping enables data collection on consumer preferences, reviews, ratings, and other market-related information. This data can assist businesses in understanding customer behavior, identifying market trends, and making data-driven decisions.
Why Use Python for Flipkart Data Scraping?
Python’s simplicity, extensive library support, readability, and strong community make it an excellent choice for web scraping tasks. It balances ease of use and powerful functionality, allowing developers to extract and manipulate website data efficiently.
While there are several programming languages suitable for web scraping, Python stands out for the following reasons:
- Ease of Use: Python’s syntax is simple and easy to understand, making it beginner-friendly. It eliminates the need for complex syntax elements like semi-colons or curly braces, resulting in cleaner and more readable code.
- Rich Library Ecosystem: Python offers libraries and frameworks specifically designed for web scraping tasks. Popular libraries such as BeautifulSoup and Scrapy provide powerful tools and methods for extracting and manipulating data from websites.
- Dynamic Typing: Python doesn’t need to declare variable types explicitly. This flexibility allows for faster development and easier experimentation during the web scraping process.
- Readable Syntax: Python’s syntax resembles English, making it highly readable and intuitive. Using indentation to define code blocks enhances readability and ensures a clear structure for web scraping scripts.
- Concise Code: Python’s concise syntax allows you to accomplish complex tasks with fewer lines of code. It reduces development time and increases productivity, making it an efficient choice for web scraping projects.
- Strong Community Support: Python has a large and active community of developers who can provide assistance and guidance. Online forums, documentation, and community-driven resources ensure you can find help and solutions to any challenges you may encounter while web scraping.
How Does Web Scraping Work?
Identify the Target URL: Determine the website URL from which you want to extract data.
Inspect the Page: The Flipkart Product Data Scraping Services first use web browser tools or developer tools to inspect the HTML structure of the webpage. It helps identify the specific elements containing the desired data.
Locate the Data: Analyze the HTML structure and identify the HTML tags, classes, or identifiers associated with the data you want to extract. It could include text, tables, images, links, or other elements.
Write the Code: Utilize Python’s web scraping libraries, such as BeautifulSoup or Scrapy, to write code that fetches the HTML content from the target URL, parses the HTML, and extracts the desired data based on the identified elements.
Execute the Code: Run the Python script or code to initiate the web scraping process. The code will send a request to the URL, retrieve the HTML content, and extract the specified data.
Store the Data: Once extracted, you can store it in a suitable format such as CSV, JSON, a database, or any other preferred format for further analysis or use.
How to Scrape Data from Flipkart?
We will use the following libraries to scrape data from Flipkart Website using Python.
Libraries Used
Selenium: Selenium is a web testing library that enables the automation of browser activities. It is helpful for tasks such as web scraping and testing, requiring automated interaction with web pages. With Selenium, you can simulate user actions like clicking buttons, filling out forms, and navigating websites.
BeautifulSoup: BeautifulSoup is a Python package designed explicitly for parsing HTML and XML documents. It provides a convenient way to navigate, search, and extract data from the parsed document structure. BeautifulSoup creates a parse tree, making accessing specific elements easier and extracting desired data from HTML or XML pages during web scraping.
Pandas: Pandas is a powerful Python library for data manipulation and analysis. It offers high-performance data structures like DataFrames, ideal for organizing and processing structured data. Pandas can extract data from various sources in web scraping and store it in the desired format, such as CSV, Excel, or databases. It also provides data cleaning, transformation, aggregation, and statistical analysis functions, enabling in-depth exploration of the extracted data.
Step 1: Find the Desired URL
Here, we will extract the Flipkart website to collect the laptops’ prices, names, and ratings. The URL for this page is
https://www.flipkart.com/lenovo-ideapad-3-intel-core-i3-11th-gen-8-gb-512-gb-ssd-wind[…]pn=sp&ssid=s5omk5xe680000001688710257903&qH=d974031e5523989b
Step 2: Inspecting the Page
The data lies within the tags. So, we will first inspect the page on which the data lies. To inspect the page, right-click on the element and then on Inspect.
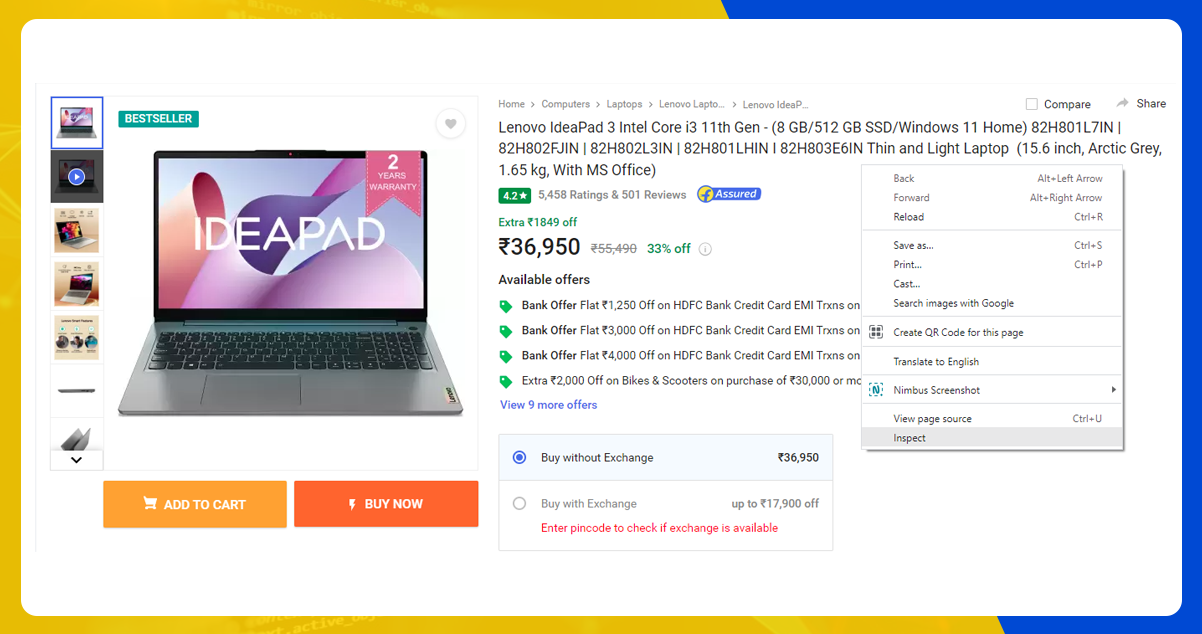
After clicking on the Inspect tab, you will find Browser Inspector Box.
Step 3: Finding the data you Want to Extract
Here, we will extract the Price, Name, and Rating within the ‘div’ tag.
Step 4: Write the Code
For this, we will create a Python file by opening the terminal in Ubuntu and then typing geditwith.py extension.
We will name the file ‘web-s.’
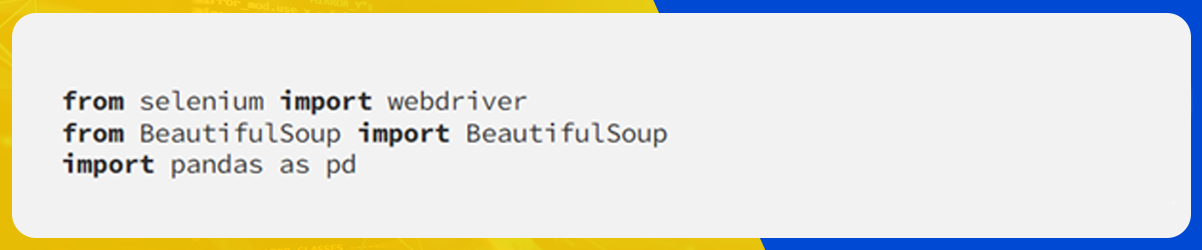
gedit web-s.pyWe will import all the necessary libraries.
We will set the path to inspect the Chrome driver.
driver = webdriver.Chrome ("/usr/lib/chromium-browser/chromedriver")You can refer to the below code to open the URL
Now, it’s time to extract the data from the website. The data we want to extract lies within < div> tags. Refer to the code below:

Step 5: Run the Code and Extract the Data
Use the below command to run the code.
python web-s.pyStep 6: Store the Data in a Desired Format
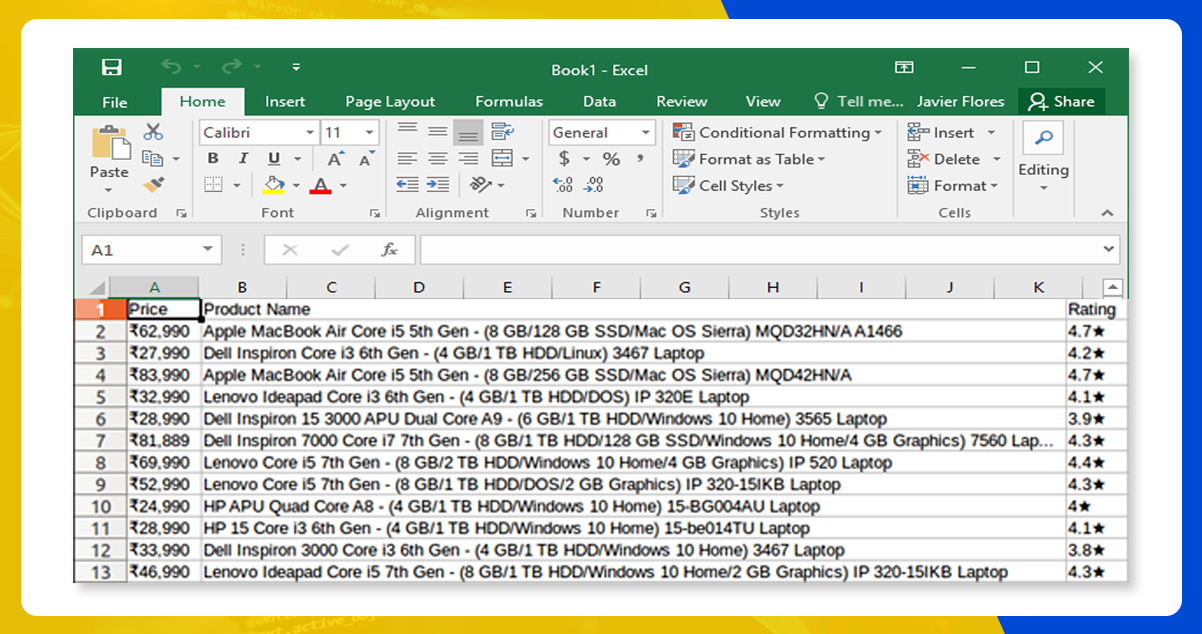
After extracting the data, store it in the desired format. Here, we will store the extracted data in a CSV format.

We generated the file in the name ‘products.csv.’
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.
#ScrapeDataFromFlipkartWebsiteUsingPython
#scrapeFlipkartproductdata
#FlipkartProductDataScrapingServices
#DatascrapingfromanEcommercewebsite