How To Crawl Amazon Website Using Python Scrapy?

Crawl products from Amazon.com with Python Scrapy. Download Meta Information and Images for every item available in the pre-defined list.
Project Overview
Artificial Intelligence heavily relies on the data, and it’s about quality. However, there is a big problem with lacking data in Machine Learning. AI needs specific amounts of data for practical analysis, performance, and training; if data adequacy is lacking, this won’t become possible to complete a dependable project. Amazon’s site is a collection of an extensive range of data kinds. This has high-quality data, including texts or images, electronic items, and all types of fashion products. All these could be very useful in making smaller-scale Machine Learning or Deep Learning Projects. With this project, we would crawl amazon.in the website to download images for different user input types. Our project will automatically make folders or download pictures and the meta.txt file for all items. In addition, this project could get used for scraping data from different web pages.
Let’s start the proceedings…
Import Libraries
We should be utilizing Python and Scrapy language with a few of the libraries with some knowledge about webpages. We would be creating a Spider from the Scrapy library for crawling a website.

Create a Spider
imghow-to-crawl-amazon-website-using-python-scrapyCreate-a-Spider.jpg

Now, let us define the constructor technique for a Spider class. The method asks a user to input categories that require to get searched separately using white spaces. All these categories would be searched using the spider on a website. We are producing a URL link for all items and save in the listing for easy access for a loop. We are utilizing a start_urls list for storing the starting URL and other_urls for storing the future URLs depending on user inputs. We have a counter variable for counting the complete URLs generated that will get used in the later procedures.

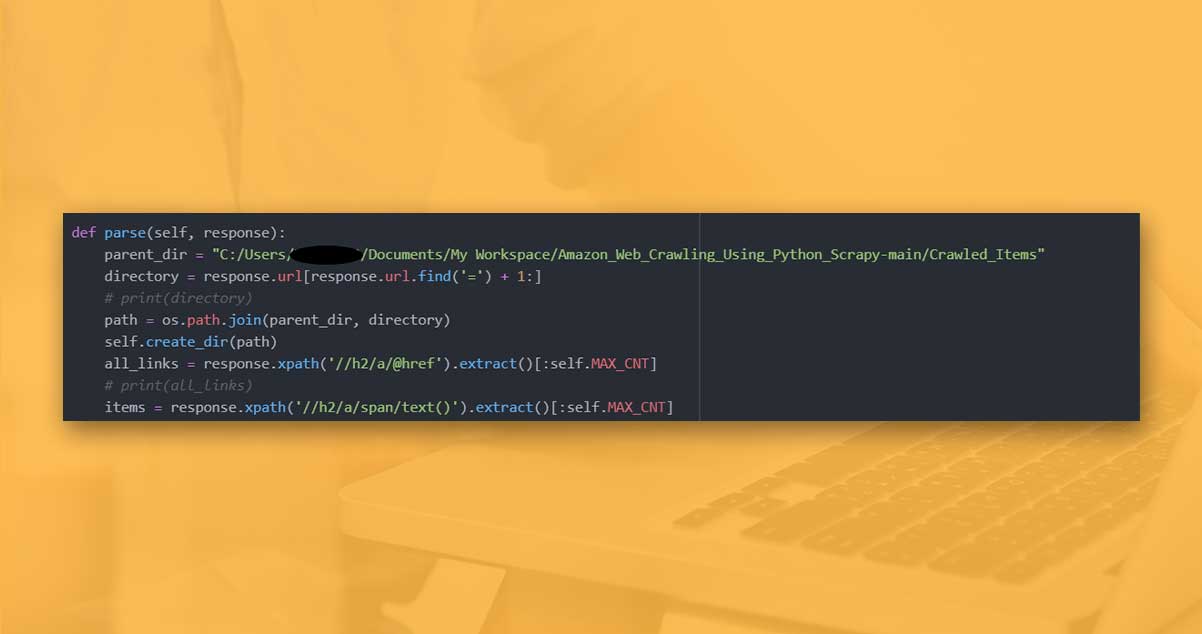
After that, we shall outline a method named parse. The technique would request a webpage with a URL available in the start_urls listing and get a response in a response variable. We need to stipulate the complete path of directories where we can store the downloaded text and images. This needs to get joined using ‘/’ before ‘’ windows characteristics. Then, we shall get an item name with a response.url, find the character ‘=’, and scrape the URL substring. For a user’s input mobile:-
The requested URL would be in the form of https://www.amazon.in/s?k=mobile, with the same URLuld be in a response t also. Therefore, we get an item name from there.
Using the item name, we will make a directory within a parent directory. xpath is a named selector in Scrapy, and it is used for scraping certain information from the webpage.
Here, we must understand that xpath would provide us data from the HTML webpage using tags, which we pass within. For instance, xpath(‘//h2/a/@href’) would give us information within the ‘href’ attribute within the ‘a’ tag in the ‘h2’ tag. We shall utilize the extract() function to get the information. Therefore, this information gives a link for the items that appear when the category gets searched, for example, Mobile. Here, we limit data to 20 items as we wish to get the initial 20 appearances. Correspondingly, we get item names under every category to make subfolders within the class. Here, we limit the item name listing to 20.
The example category is Mobile, and the item names include Samsung Galaxy M33 5G (Color: Emerald Brown with 6GB & 128GB Storage), etc., and all_links would have url-links to those items.
After that, we iterate over the all_links listing to find every item. After that, we perform specific alterations on item names items as they are long and have particular unwanted chars. After that, we continue yielding Requests till we finish the links. The requests object should send a response for parse_pages methods and pass a path like dictionary parameters. Other parameters are also important in the context of this project and are essential for smoother requests to domains.

We have used a parse method for crawling the webpage having a category while the parse_pages process for crawling webpages for every item under the category. With the parse_pages method, we first retrieve text for every item by performing some operations using Regex (regular expressions) modification and xpath selection. The text modifications are essential to remove particular chars and find text in readable formats. After that, we write this text data in the file called meta.txt. After completing the project, you can get samples of the text files and how they get saved.

Using this code, we scrape image URLs that can be utilized to download and save in a local folder. As we could request a webpage and this information many times, we could be blocked from a domain. Therefore, we add the sleeping time of about 10 seconds if a domain server initially refuses the connection. We also use the Requests object to pull replies for the following URLs in the other_urls listing.

The create_dir technique has been made to automatically make subfolders depending on the items under every category.

Wonderful! Now, as we get the spider created and saved. Let’s run that and see its results.
To run a spider, we need to run an anaconda prompt or command prompt from a directory where this has a scrapy.cfg file. The configuration file for Scrapy and a spider Python file are available within the spiders’ folder with this directory. Do a scrapy project using the spiders.py file. Although creating the new project using scrapy is easy, this could be looked at here.
To run a spider, we have to run a command called scrapy crawl spider_name. Here, it might be scrapy crawling amazon_spider. Run that from the directory in which the scrapy.cfg file is available as given below:-

Now, you can see the data coming, like bot names and more. However, the quick stop once that outputs, “Enter items you need to search separated by spaces: ” … Now the time is there to enter every category you need to search; in the case here — “mobile tv t-shirts” all are separated by the spaces. Press enters it; now the prompt would output different information, mainly having the requests sent with the amazon.com domain. The graphical changes you could notice in the directory where you get specified in saving files. Here, it was the Crawled_Items folder.
Wonderful! Our output would soon become ready! Let’s get some glimpses of the downloaded content….
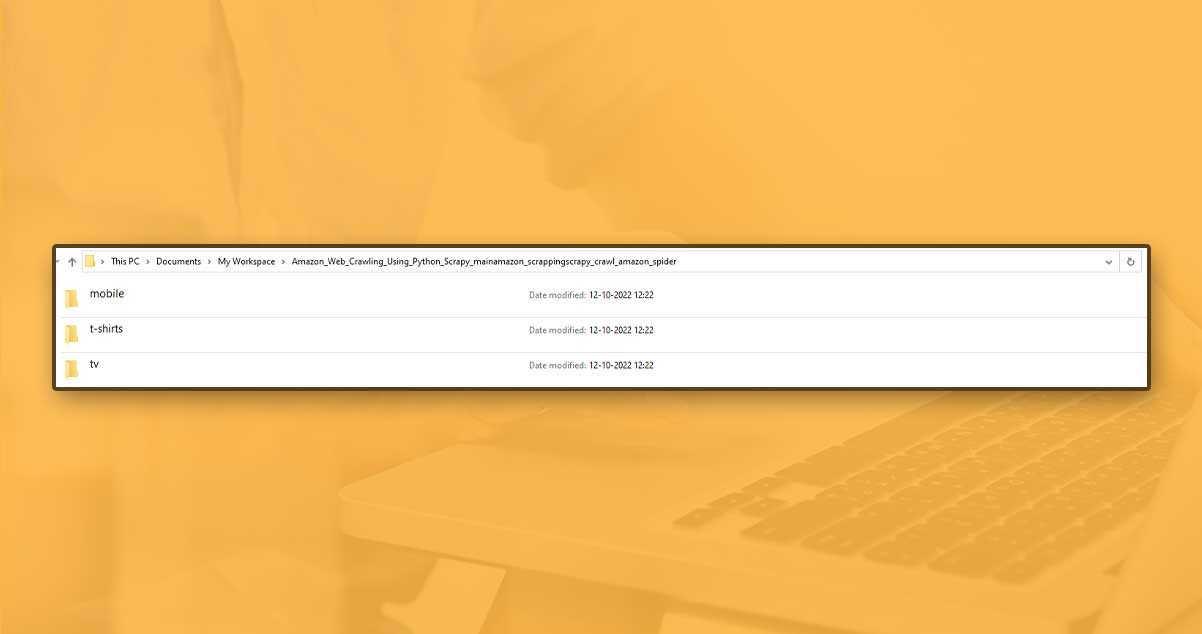
Folder created for every category.
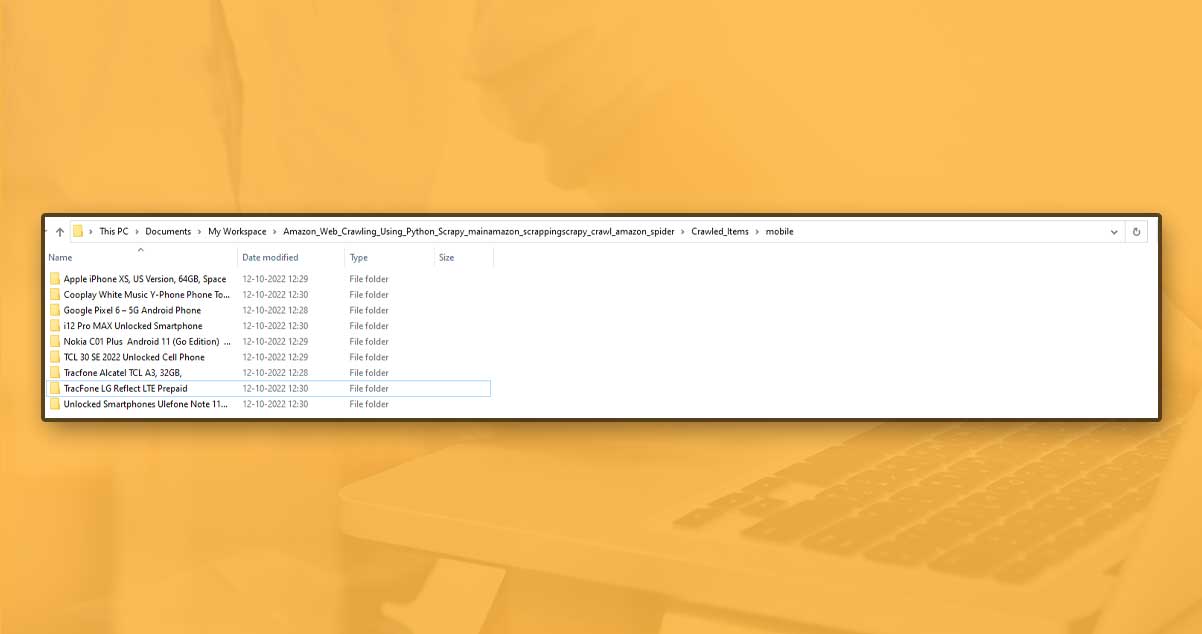
Under every category, one bunch of folders for every items at maximum 20.
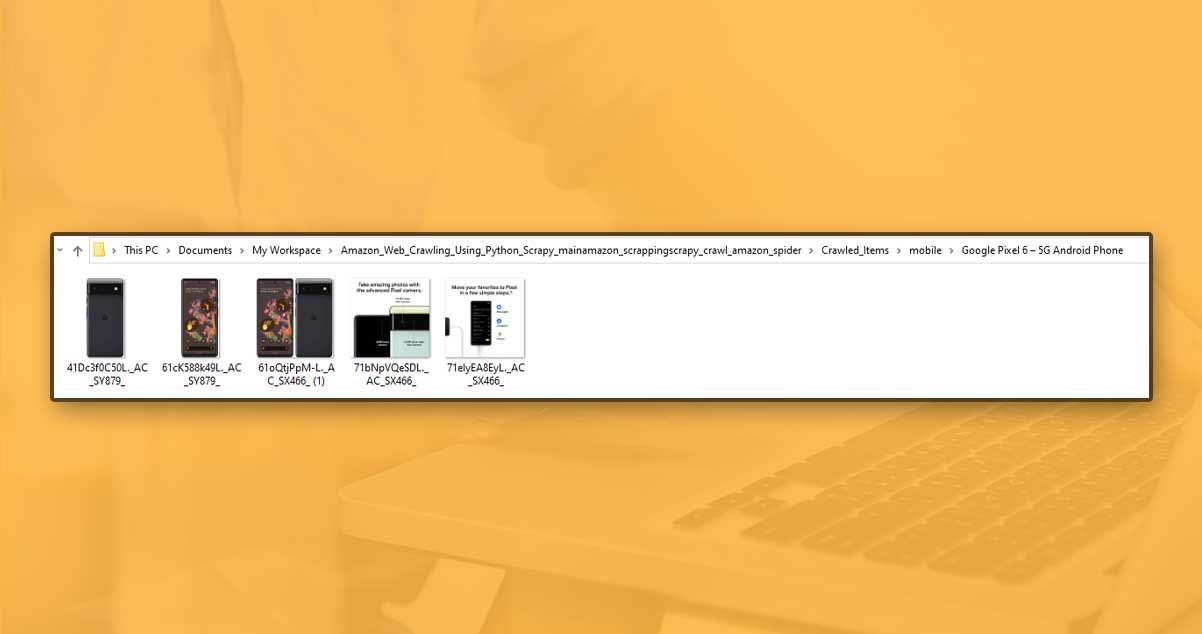
Under every item, some images with meta.txt file having informational features of items.
Meta.txt file having information:-

Therefore, this marks the end of the project
Happy Coding!
For more information, contact iWeb Data Scraping. Contact us for web scraping and mobile app scraping service requirements!
#CrawlAmazonWebsiteUsingPythonScrapy
#CrawlproductsfromAmazon
#Scrapylibraryforcrawlingawebsite