
Technology
Why Cloud Computing’s Next Leap Will Redefine Digital Power
Unveiling the New Era: A Glimpse into 2026’s Cloud Computing LandscapeIt is an early spring morning in Silicon Valley, 2
A quality-gated publishing platform where verified experts share deeply researched, original articles across every major industry.
Unveiling the New Era: A Glimpse into 2026’s Cloud Computing LandscapeIt is an early spring morning in Silicon Valley, 2

Electrifying Momentum: The Unsung Hero of EV ExpansionOn a bustling assembly line in Stuttgart, Germany, a precise elect

Unveiling the Pulse of Gaming in 2026In the bustling heart of Tokyo’s game development hubs and the sprawling studios of

The Hidden Power of Food: Beyond NourishmentImagine sitting down to a meal that not only satisfies hunger but also influ

In the Trenches: The Modern Legal BattlefieldOn a brisk morning in April 2026, a landmark case unfolded in New York’s Su

Unlocking the Mortgage Maze: Why Rates Matter More Than EverImagine standing at the threshold of your dream home, only t

When Victory Slips Away: The Unseen Cost of Common Sports MistakesIn the high-stakes world of competitive sports, even t
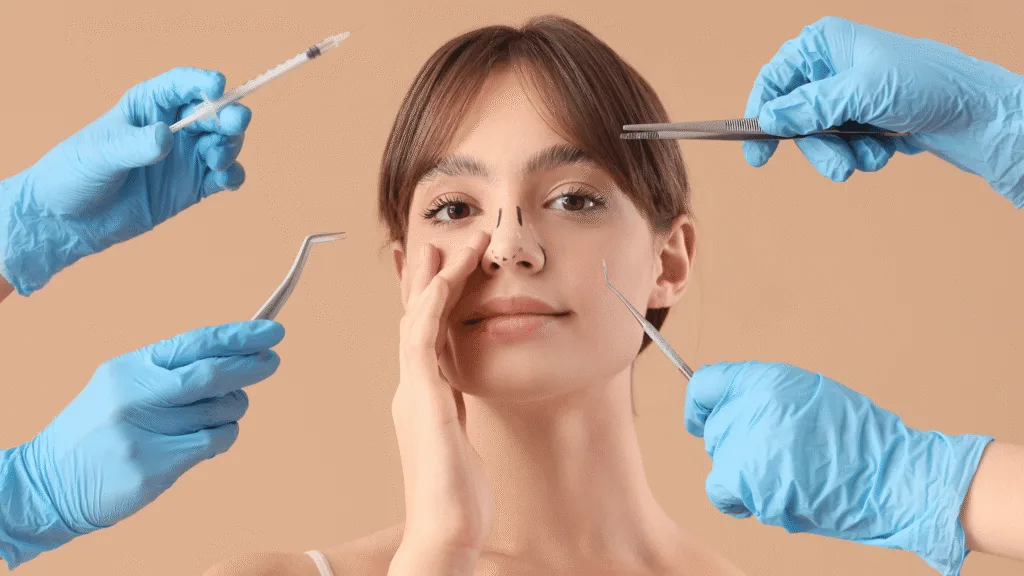
The nose is one of the most noticeable facial features and plays an important role in breathing and facial symmetry. Whe

Starting Strong: The Reality Check on Personal Finance TodayImagine a typical morning scene: a young professional opens

Opening Spotlight: When Fame Meets UnpredictabilityAs May 2026 unfolds, the world of celebrity news is pulsating with a

Indian businesses expanding internationally face a specific compliance challenge: Indian GST, TDS, and e-invoicing requi

The New Pulse of the Internet: A 2026 Web3 SnapshotOn a brisk April morning in 2026, a virtual conference convened over